
Accomplishments
Our team has been needing a concrete metric for a very long time now. The most important thing I’ve done this week is clearly defining model throughput and model throughput per dollar::

The underlying goal of this project is to produce a system that can train large batches of distinct machine learning models very fast and at a low price point. Processing more models in the same amount of time, processing the same number of models in less time, and processing the same number of models in the same amount of time with a cheaper setup should all increase the score. Throughput and throughput per dollar together reflect all three of these traits, and thus make good metrics to quantify the improvement that our system will make over existing systems (CPU and GPU).
The throughput metric is also useful because it is additive: if we combine two systems, each with throughput T1 and T2, then the total throughput of the system will be (T1 + T2). This will allow us to quantify the scalability of our system by calculating the difference between actual system throughput and the throughput for a single Worker board multiplied by the number of workers. This metric will quantify the overhead that our system faces as it scales.
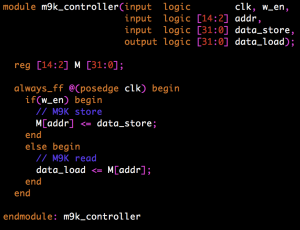
This week, I also did research on the M9K blocks. I’ve had some trouble finding example code for these, and discovered this week that Quartus will synthesize modules that act like RAM onto M9K blocks implicitly. Our actual M9K controller will be based on this starter code:
Schedule and Accomplishments for Next Week
I’ve made some good progress on memory modules for the hardware, but there is still piles of work to do on it. Next week, I want to start working on the FPU Job Manager, which will be the hardest working component that we need to make.