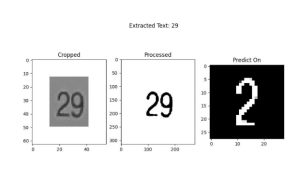
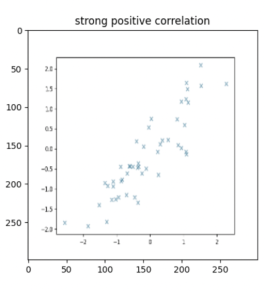
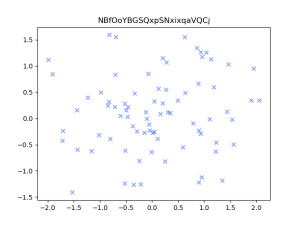
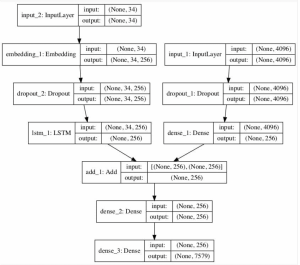
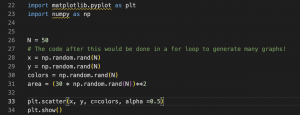
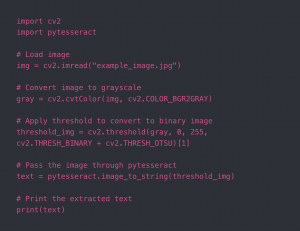
This week, I finalized and retrained/saved the graph detection and slide matching models, continuing to make changes to hyper parameters and values for pre-processing. The main task this week was dealing with issues in the graph description model. I was able to train the model last week and get results on input scatterplots and line graphs, and during the same run, visualize results. However, when I tried to save the model and reload it (so that we wouldn’t have to retrain every time we wanted results), I faced several issues. The root of these issues is that in Keras, only the most basic type of model (a sequential model with fully connected or convolutional layers) can be saved and loaded in this way. Since my architecture is significantly more complex and consists of a CNN followed by an encoder/decoder network, Keras would not allow me to save and reload the model with its weights after training to be used for inference.
I spent several days trying to work around this issue by looking into the Keras documentation and Stack Overflow, but in the end decided that it would be better to use a different framework for the model. I then translated all of my code into PyTorch, in which it is much easier to save and load models. I then retrained the model.
Once I did this, I also worked on the integration – I completed the slide matching integration with Aditi earlier in the week, and I worked on the graph detection and description pipeline (I had to combine them into one full system since we are using the extracted graphs from detection for the graph description). This pipeline is now complete.
I finished on schedule and all that is left for this coming week is to try to make minor tweaks to perhaps improve the slide matching accuracy further and do some user testing so that we can include results for that in our final report. We also need to finish up our final report and do some testing tomorrow of the full system before the demo.