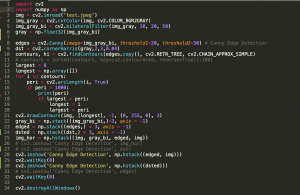
Most of my work this week was in trying out further model training configurations to account for some false positives we discovered in our design.
On Sunday, I worked on adding details of our old approach and restructured approach, our computer vision training accuracy – the complete solution and the final gantt chart for up until the last week. From Monday to Wednesday I was busy with exams and deadlines for some other classes, so I instead put some time into figuring out what tasks we had left as a group and assigning overall priorities to tasks during this time. Work between these few days took about 4-5 hours to compile everything together.
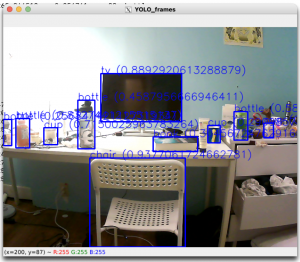
From Thursday onward, we noted that the model was giving some high confidence false positives that the sample thresholding couldn’t account for. Specifically, some occurrences of backpacks were detected as people with >60% confidence or the TV in the room came up as a dining table with >60% confidence as well.
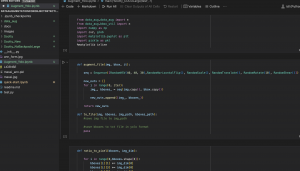
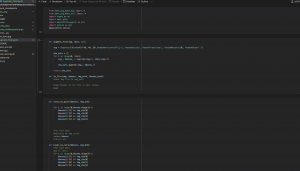
This was when I realized our custom dataset didn’t have enough background information, or samples of objects not to look for in the images – such as TV, or phones etc. Aditi suggested using the Pascal VOC dataset to add to our training, adding in some needed background information. So from Thursday onward, I worked on retraining the model with various combinations of the VOC dataset and our custom dataset. To prep, I wrote a script to eliminate images without tables/chairs/people from the VOC dataset, drop instances of classes we weren’t looking for and to switch the class mapping to our custom class mapping. With the larger dataset I decided to switch over to a larger AWS training instance (P2.xlarge -> P3.2xlarge). I encountered some problems with training as my Allocated CPU limit on AWS didn’t account for the larger instance. Unfortunately, I found this out in the middle of training with my connection closing out and I was unable to restart any instances to save any data. i immediately sent in a new CPU limit increase request to AWS but most of my time during Thursday/Friday was thus spent trying to save all the training data that was stored across the two instances I had (solved using an S3 bucket). In total, I spent about 8-10 hours from cleaning the Pascal VOC dataset to running training on Pascal, to dealing with the AWS server issue.
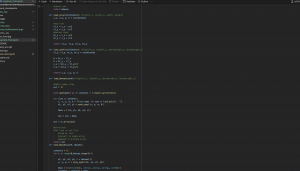
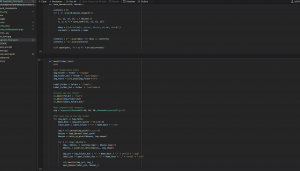
Another thing we noted with regards to training was how switching class mappings and the overall output layer requires some retraining from the model to remap to the new mapping scheme while also training for higher accuracy in the target classes. Because the classes we are targeting are already part of YOLO’s pretained class mappings (COCO labelling), training using those existing mappings and our dataset will help with the overall accuracy of the model (specifically lowering the rate of false positives as those items now have a specified class). I spent up to 7-10 hours on Saturday reprepping our data to work with the COCO labelling scheme. This involved redownloading our re-labelled custom dataset, running my random data augmentation script to increase the dataset size, writing a new script to switch to the COCO mappings and running the dataset through the remapping script. On the VOC side as well, I rewrote the VOC remapping script to remap to COCO labellings. From here, I backed up the datasets to an S3 bucket as well.
On Saturday as well, there was an issue trying to use my spot instances to train/move data. Spot capacity works with leftover available CPUs, and no spot capacity was available in the us area regions where my instances were. I thus also spent time Saturday working with Google Colab to set up a notebook to move our training to. By the night however, there was spot capacity available so I was able to start training.
I tested 4 configuration of training to start off with, to test how the model would train in terms of accuracy improvement:
- Custom for 50 Epochs w/Backbone (Layers 1-10) Frozen
- Custom for 50 Epochs w/Backbone (Layers 1-10) Frozen + Custom for 10 Epochs w/Layer 1-22 Frozen
- Pascal VOC for 50 Epochs w/Backbone (Layers 1-10) Frozen
- Pascal VOC for 50 Epochs w/Backbone (Layers 1-10) Frozen + Custom for 10 Epochs w/Layer 1-22 Frozen
Training is still ongoing, but so far the Custom Training using COCO labelling for 50 epochs with just the backbone frozen seems to have good performance.
Moving into the final demo and onward, I will be training the rest of these configurations and working on compiling my training data for the final report. In addition, working with my team to test remaining metrics and work on the final report/video.