Team status report, 10/12/2022
Firstly, we finished the slides for our final presentation. This was also a good opportunity to discuss and plan work to get us ready for the final demo.
This week we began preparing for our demo. Firstly, we have started integrating all the different parts of our project. We also came up with a plan to collect data from users in the next few days, and also during our demo, which will be a great opportunity to do so, as there will be many people there who will interact with the project.
We have also started to write the final report. We are in the process of generating graphs and gathering old meeting notes that will contribute to the final report.
Angela’s status report, 10/12/2022
The beginning of the week, I and my team worked on our powerpoint for the final presentation. As I was the one who would present, I wrote down an outline for the points I wished to make during my presentation and made sure to include what my teammates wanted said.
This week, I spent my time working on the parallelization of a timing bottleneck in the audio processing module. This was a part that parses the audio file for the sliding DFT for each key. I am going to test different numbers of threads on our AWS instances to find the one with the best speedup. The threading library was used to facilitate this. This was a very good learning opportunity for me, as beforehand I was not aware one could be able to enable parallelism in a high level language like Python.
I implemented some new decay calculation methods in my code. Unfortunately, this caused some bugs that made my module non-functional. I hope to resolve these by the demo.
I also spent time helping John Martins debug the virtual piano. There was a bug where only the first element of the array was being passed to the end of the pipeline. Fortunately this was resolved and the piano is able to now play more than one key at once.
Marco’s Status Report 12/10/2022
This week, I finished implementing the audio reconstruction pipeline which allows us to listen to the audio being extracted by the SDFT bins.
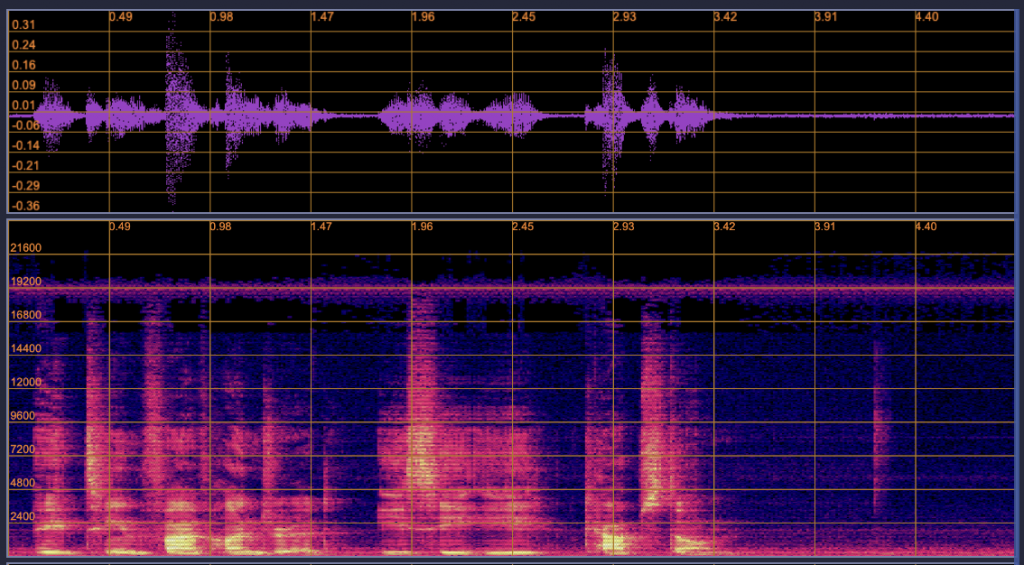
As a reminder, my goal was to take an original audio of someones voice (see first audio sample below), and the extract the frequencies present in a user’s voice that correspond to the frequencies of piano keys. However, we’d have no idea if we’re extracting enough information by only using the power present at the piano key frequencies — therefore we needed to somehow reconstruct an audio file using the frequencies we picked up.
John’s Status Update (12/10)
This week I have been focused on the final integration steps for the web app, and in particular, the transfer of arrays from the note scheduler (that describes what notes to play at which sample time) to the front-end piano such that the correct set of key audios can be triggered all together. In this vein, I have worked to set up the infrastructure of receiving these 2-D arrays and playing through them with the corresponding piano audio files. I have tested the audio playback on several arrays and been able to reproduce the proper sounds. With the stream of data from the notes scheduler, we will be able to play the audio files necessary to recreate the audio.
I have been also working on the visualization aspect of the virtual piano such that users can see which keys are being played to create the sounds they are hearing. Here is a snippet of the piano playing a subset of a large array of notes:

With good progress in the audio processing parts, we have been able to listen back to audio files that have been processed to only include the frequencies of piano keys. With these audio recreations, we have a good baseline to compare our piano recreated sounds with that help us guide our optimizations.
Lastly, I have been looking at AWS instances to push our finished product to and have been researching good E2C instances that will allow the webapp to have access to several strong GPU and CPU cores to perform computation rapidly. Once set up, we will be able to conduct processing and audio playback very seamlessly and efficiently. We are planning to use an instance with at least 8 CPU cores as to be able parallelize our code through threading.
What is next is to polish the integration and data transfer between the 3 main sections of our code to optimize the user experience and push everything to the AWS instance.
John’s Status Report (12/3)
This week, I focused on attempting to recreate the input audio using piano key audio files. To do this, I needed several things: audio files for all keys on the piano (in order to reconstruct the sounds), a piano design for visualization on the web app, and JavaScript functions to interpret the note scheduler list and play the correct notes at each sample.
In terms of the audio files, I finally found all the necessary notes from a public GitHub (https://github.com/daviddeborin/88-Key-Virtual-Piano). This has allowed me to extract each note and utilize them for playback. With these files, I can play many in parallel, choose what volume to play them at (using information encoded from the notes scheduler), and whether I need to repress them or not on any given sample.
In terms of a piano visualization design, I was able to get a 69-key piano formatted for our webapp after drawing inspiration from and wrestling with the HTML, CSS, and JavaScript code from the Pianolizer Project (https://github.com/creaktive/pianolizer). Now, we are able to see a piano on our web app as the sounds are being played.
Up next, I am planning to tie everything together with the proper functions that allow for playing the notes in parallel for each time sample to recreate the audio. I will be using the piano design to change the color of the keys currently being played so users can visualize what notes are being played as they hear them. Lastly, I will be working with Angela to incorporate a speech-to-text analyzer for both the input and output audio to see if the program can capture the word being ‘spoken’ by the piano.
Team Status Report 12/3
This week, we revisited our rescoped project and laid out the plans amongst ourselves and the professors. In last week’s team status report, we went on a deep dive of our new scope (linked here for reference: Last Week’s Report).
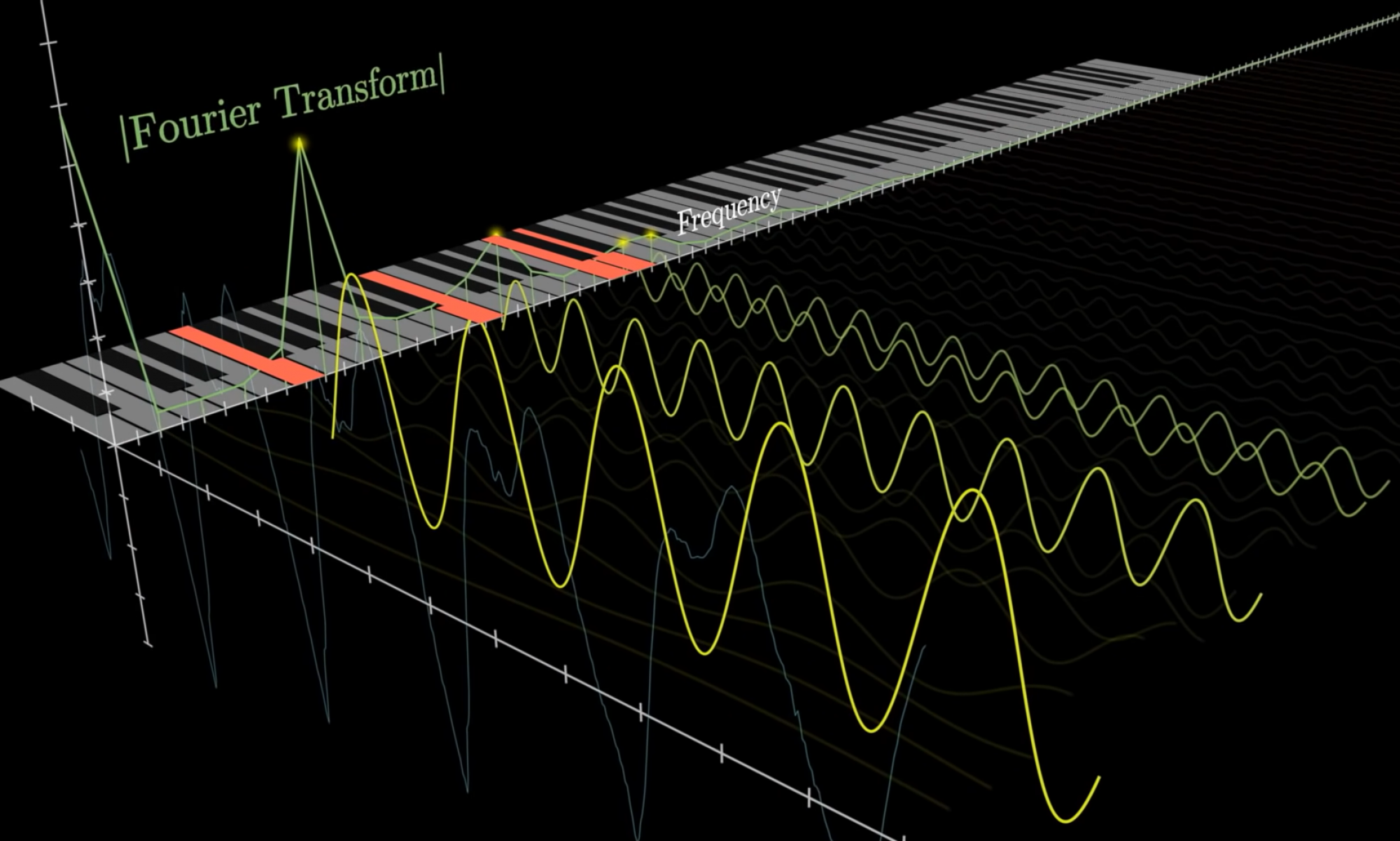
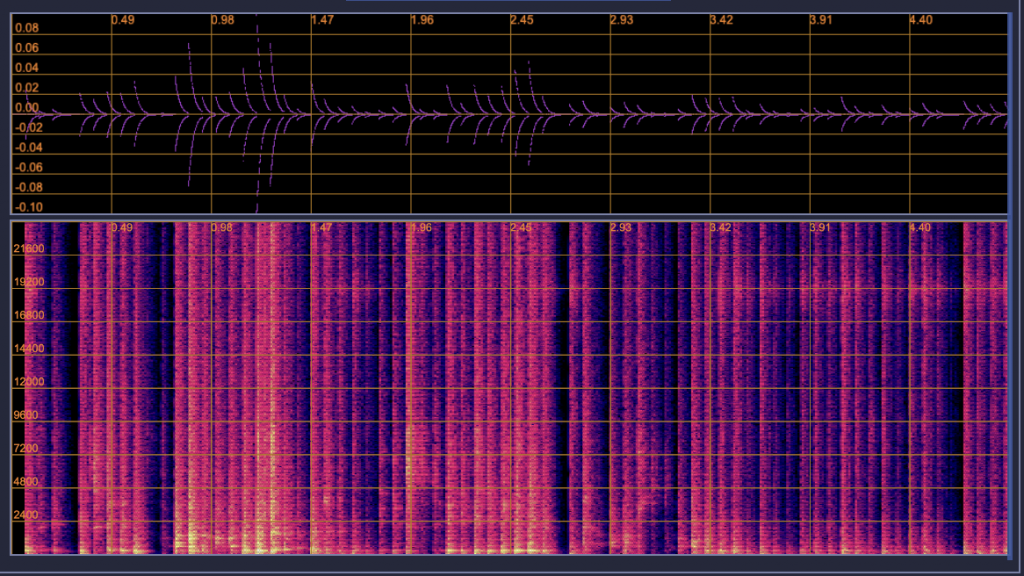
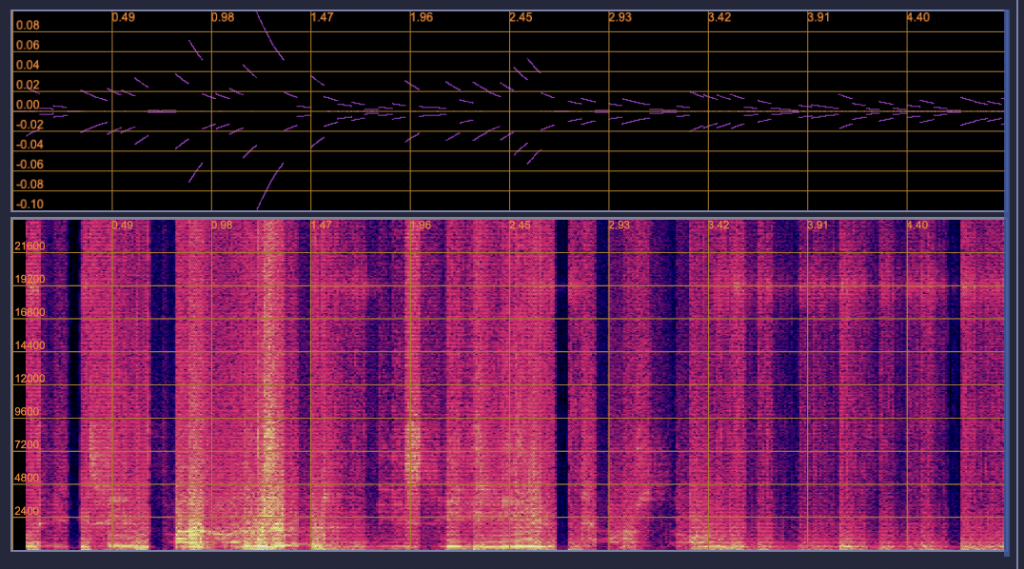
In terms of current progress in our overall project, we have focused efforts on rounding out playing back the processed audio using virtual piano notes through our web app. For the audio processing component, the system successfully implements a Sliding Discrete Fourier Transform to be able to capture amplitudes from the input audio at each specific piano frequency. This has allowed for accurate reconstruction of the audio using just the frequencies at each piano key. Below we have graphs showing the comparison of the reconstructed audio (left) and the original (right) in the above image. If the image quality permits, you can see how, by only using the piano keys, we are able to create a very similar Time vs. Frequency vs. Amplitude graph.
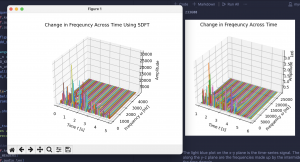
In this graph we have processed an audio file of just 1 piano key. We can see based on our audio processing the spike at the frequency of that key and the corresponding spectrogram showing the brightest color for that frequency. This was done as a way to prove that our processing is accurately capturing values for the input frequency and a bit of a sanity check.
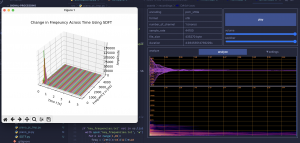
For the Web app and note scheduling, we have been discussing the idea of incorporating the natural decay of piano keys to determine how we will determine whether a note will be re-pressed at any given sample and how we can playback the audio at different volumes using our web app. We have acquired audio files for every note, and using the 2-D array from the scheduler representing which of the 69 keys to play at each sample, we will be playing the corresponding audio file to recreate all the notes played at each sample.
This upcoming week, we are planning to take measurements of note accuracy, fidelity with understanding speech through the audio playback, and performing an inverse FFT on the audio (not using the piano note audio files as a medium) to compare the recreation using piano notes. As we wrap up our project, we are also preparing our presentation, final paper, and fine-tuning our performance metrics to meet the requirements we set for ourselves.
Marco’s Status Report 12/3/2022
Before Thanksgiving break, we re-scoped our project to use a fully digital interface, and I also laid out my approach to collecting accurate information about the frequencies present at the corresponding piano keys. Since then, I finished implementing the library and have been generating the tab separated duty cycle values we’re hoping to pass onto Angela for her work. Here’s screen shot confirming the frequencies we’re getting match the one’s we saw originally at the beginning of the semester! Now I’m trying to reconstruct the output audio using the averaged frequency components we’re collecting.
Angela’s status report, 2022/11/19
This week, my teammates and I decided to fully commit to the virtual piano. For my implementation of the note scheduler, this required small adjustments. Firstly, I removed the limitation of 5 volume levels, as well as the requirement of a minimum volume of 5N, since we don’t have solenoids anymore. This will allow us to reach a wider range of volumes through both extending the floor of the lowest volume as well as allowing for more granularity.
Furthermore, I’ve started to read documentation in preparation to write another part of the project. My teammates and I discussed further testing and presentation methods for our final product, and we’ve decided to use speech recognition both as a testing method as well as a way to present our work. We plan to run speech recognition on both the initial input as well as the final output as a way to measure fidelity. We will also use speech to text modules to create captioning to present our product to the user, in order to allow for easier recognition of what the piano is “saying”. I’ve examined the Uberi module, which seems appropriate for our project. An alternative is wav2letter which is in C++ and offers faster latency. I will discuss latency issues with my teammates at our next meeting to determine where the bottleneck is.
Marco’s Status Report for 11/19/2022
This week, we decided to pivot away from the physical interface — more information on that can be found on our team status report for this week. In light of this, I’ve been working with John and Angela to figure out how my works changes.
Here are my expected contributions “re-scoped” for our virtual piano interface:
- Take in recorded audio from web app backend
- Generate three files
- A series of plots that give information about the incoming audio and frequencies perceived by the system
- A digital reconstruction of the original wav file using the frequencies extracted by our averaging function
- The originally promised csv file
- Metrics
- Audio fidelity
- Using the reconstructed audio from the signal processing module, we can interview people on whether they can understand what the reconstructed audio is trying to say. This provides insight into how perceivably functional the audio we’ll generate is (reported as a percentage of the successful reports / total reports).
- Generate information on what percentage of the original frequencies samples are lost from the averaging function (reported as a percentage of the captured information / original information)
- Audio fidelity