In addition to addressing how our product meets market needs in terms of considerations to public health, safety, and welfare, as social, and economic factors related to the system of production, distribution, and consumption of goods and services, our group would like to explore public concerns from a different perspective. Hence, A was written by Steven, B was written by Surya, and C was written by Grace.
Part A: With consideration of global factors, NutrientMatch can be used by just about anyone across the globe, whether or not their wellness goal consists of consuming more calories or better keeping track of the types of foods they are consuming daily. Regarding younger adults, as fitness is becoming a bigger trend with the emergence of technology and the expansion of gyms, more of these people are aware of their nutrient intake. Our product is heavily targeted towards this group since they tend to live with roommates as opposed to other family members. With this in mind, it is easier to get foods mixed up when groceries are purchased separately. NutrientMatch is able to track each user’s food inventory as soon as they are logged in to avoid these confusions. On the other hand, family members may also want to use this product to track their own intake. Our product can also be used by those who are not as tech-savvy as others. The usage process is easy: after each food item is either scanned or classified and weighed, it is automatically forwarded to the cloud database which will make backend calculations to be displayed on the webpage for users to see. Hence, while NutrientMatch is not a necessity in people’s lives, the increasing trend of physical wellness makes it a more desirable product overall.
Part B: Cultural considerations in the design process are crucial to making NutrientMatch an accessible and adaptable product for those around the globe. The most obvious example that comes to mind is the acknowledgment of dietary preferences in cultural and religious contexts, including but not limited to plant-based diets and veganism, Halal foods in Arabic Culture, and Kosher foods as delineated by the Jewish faith. To that end, we will dedicate significant resources to training a recognition model that can broadly recognize and perform similarly across a variety of testing inputs sampled across these cultural lines, so as to not perpetrate any implicit biases in the recognition process.
Another vital cultural aspect to consider is the idea of nutritional makeup and body image. Various cultures around the world prioritize specific eating lifestyles and different preferences for caloric makeup and subsequent ideas for how the ideal physique should be maintained. While some groups may prefer thinness, with an increased focus on portion control and calorie counting, in other cultures food is synonymous with hospitality and status. Despite these seemingly disparate perspectives on the notion of “ideal” nutrition, NutrientMatch should perform similarly and without bias in all scenarios. Our product will be carefully designed to avoid reinforcing specific nutritional ideals; similar to the idea above, our recognition model and recommendation algorithms will perform as intended irrespective of the actual nutritional habits of a certain user.
Finally, the notion of privacy and communication/integrity of data is an issue that crosses cultural lines as well. Some cultures view technology and its role in human life differently than others. In developing NutrientMatch, we seek to build trust with our customer base by demonstrating a commitment to the privacy and confidentiality of data; this will help us garner popularity and positive standing even amongst cultures that may demonstrate initial skepticism towards such technology. MySQL automatically hashes and encrypts the stored data in the database, and the HTTPS protocol that will be used to interact with such a backend will prevent hackers from intercepting data based on an extensive SSL certificate authorization process that checks the users and the domain name against what is listed on the SSL certificate.
Part C: Lastly, there is a strong connection between previously analyzed economic factors to environmental considerations. One of our greatest concerns when doing research for the product’s use case requirements was the high amount of foods that spoiled in the United States. This does not only directly impact the economy as people are wasting their groceries, but more foods are added to landfills. Obviously, landfills take up a lot of space and need to be managed periodically. In addition to this, landfills produce odors and methane gas that directly contribute to global warming and the air we breathe. It is important to effectively utilize all the resources we have as the global population continues to increase, and NutrientMatch can help users maximize this use by tracking every item entering their food inventory system. This reduces user stress in remembering the groceries they bought but can also help them manage what to buy next or what types of foods they are currently lacking. Besides personal health, the environment remains one of our greatest concerns and we hope that NutrientMatch encourages users to consume and productively make use of all the ingredients in their home before directly disposing of them.
Shifting towards a discussion on our team’s progress over these past two weeks, we were successful in a lot of the software design from ML to web app development. First, Steven was able to progress substantially in the ML design portion. He was able to finalize tests and validation for the soft-margin SVM formulation to distinguish between fruit and canned foods; however, there are still issues with accuracy which will need to be fixed in the upcoming weeks. Likewise, Steven made substantial progress in researching ChatGPT4 capabilities and the API to integrate its label-reading algorithms into our web app design. Everything is on if not ahead of schedule regarding the ML aspect of our project which will give us extra flexibility in fine-tuning and maximizing the results. We hope to gather statistics to support our design choices as well shortly.
Additionally, Grace was able to help Steven gather data for the ML testing portion, including feature data that would help distinguish between the packaging between fruits and canned foods, label data for training the SVM classifier, and some other relevant information that was used during the labeling of each food item. With the given issues, some fine-tuning may still need to be done further. Regarding individual progress, Grace has completed mockups for the design report and used this towards calibrating the front-end designs. Rendering functionalities between user login, user registration, user home page, and logout pages have been completed. More progress is being made on the web application database retrieval with MySQL and setting up the tables regarding what information should be displayed to users. More testing will need to be done to handle database requests and deployment to the server environment.
Surya focused on advancing the web application in advance of a functional demonstration of the basic web app features at the next staff meeting on Monday, March 11. To reiterate, the demo will focus on site navigation, front-end development, user interaction, and view routing. Some of the particular accomplishments include a refinement of the OAuth feature for registering new users through their email addresses, as well as weight-tracking visuals using the chart.js framework. Looking ahead, the team plans to develop more user interaction features; these include progress posting, friend networks, and a Websocket-based chat service.
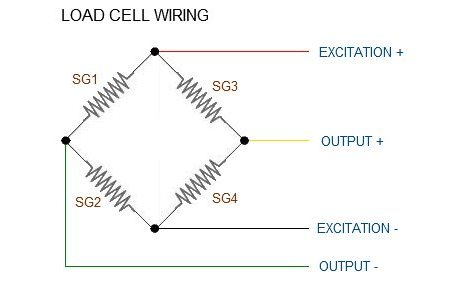
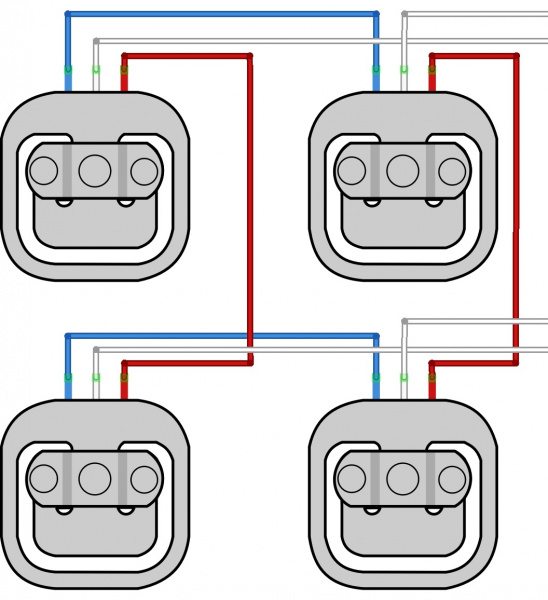
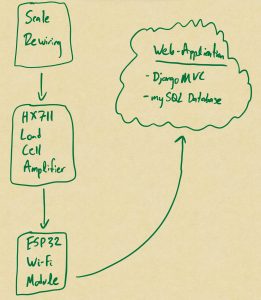
Surya also continued research on the scale integration process and will order parts this week. Despite initial hesitancy due to the unfamiliarity with market options, he compiled a list of microcontrollers, with a consideration of factors such as power consumption, pin layouts, and opportunities for streamlined design through custom SoC options. This constitutes a fascinating stretch goal, and one we look to tackle in early April, but for now, we would like to proceed as planned with our simple yet effective MVP approach with ESP protocols.
Despite the progress schedule remaining largely unchanged, we understand this is the point of the semester where we expect to make significant progress toward our product with the interim demonstration arriving soon.