- We still have not picked up our lights yet and everything else seems to be going well. Until we have more info on the lights (which we should have this week) we have the same risk for them which is: The most significant risks that could jeopardize the success of the project have not changed much so far. More specifically, the first biggest risk is not being able to properly compile and run code for controlling our light fixture automatically through our control program, which would use Flask, Python, and the Open Light Architecture framework to transmit DMX signals to the lighting system. Our concerns are due to comments given on other people’s projects attempting to control lights using the DMX protocol that the OLA framework is a little finicky and difficult to bootstrap, even though after initial setup progress should be smooth and predictable. To mitigate this risk we will be testing our setup before committing completely to OLA.
- One change that was made was we are now connecting the Pis through wifi rather than a direct ethernet cable. This change was not necessary but wifi works just as well for our purposes and is easier to implement. This change did not incur any costs.
- No updated schedule
Matt’s Status Report for 3/16/2024
- This week Thomas and I added functionality to our web socket app. I was involved in merging our queue class with the front end so that when the users request a song, it will be added to our queue and be the same for all users. The same queue is also now displayed on the front end for all users (pictures are shown on Thomas’s status report). I also was able to set up our second pi and set up communication between the two Pis. Shown in the link below: a user is requesting the song from their computer then through the web socket our first Pi receives the request then it forwards the song to the next Pi. https://share.icloud.com/photos/01b9O72-v7Uqz9KqOgRQfZ09g Communication between our Pis is important so this is good to see.
- My progress is on schedule
- Next week I hope to have a simple vetoing system so users can vote against a song and all the votes will be stored in the server. Also, we will try to integrate our backend on the app with the work Luke has been doing.
Thomas’ Status Report for 3/16/24
Thomas Lee
- This week, in collaboration with Matt I rebuilt the Web App and Queue Manager backend module for processing User requests and storing the collaborative song queue. Now, the songs and the song queue are stored in local memory by the backend process, and the queue state is forwarded to each User’s app client via their web socket connection. When a New User logs onto the app they can enter a Username to be displayed next to their song requests, and they are immediately sent a JSON payload containing the current queue. Users can send a new song request to the server through a form, and it will appear immediately on the next slot in the queue on all Users’ app views simultaneously. I also polished the frontend side of the app for better readability and queue consistency among distributed instances of the web app.

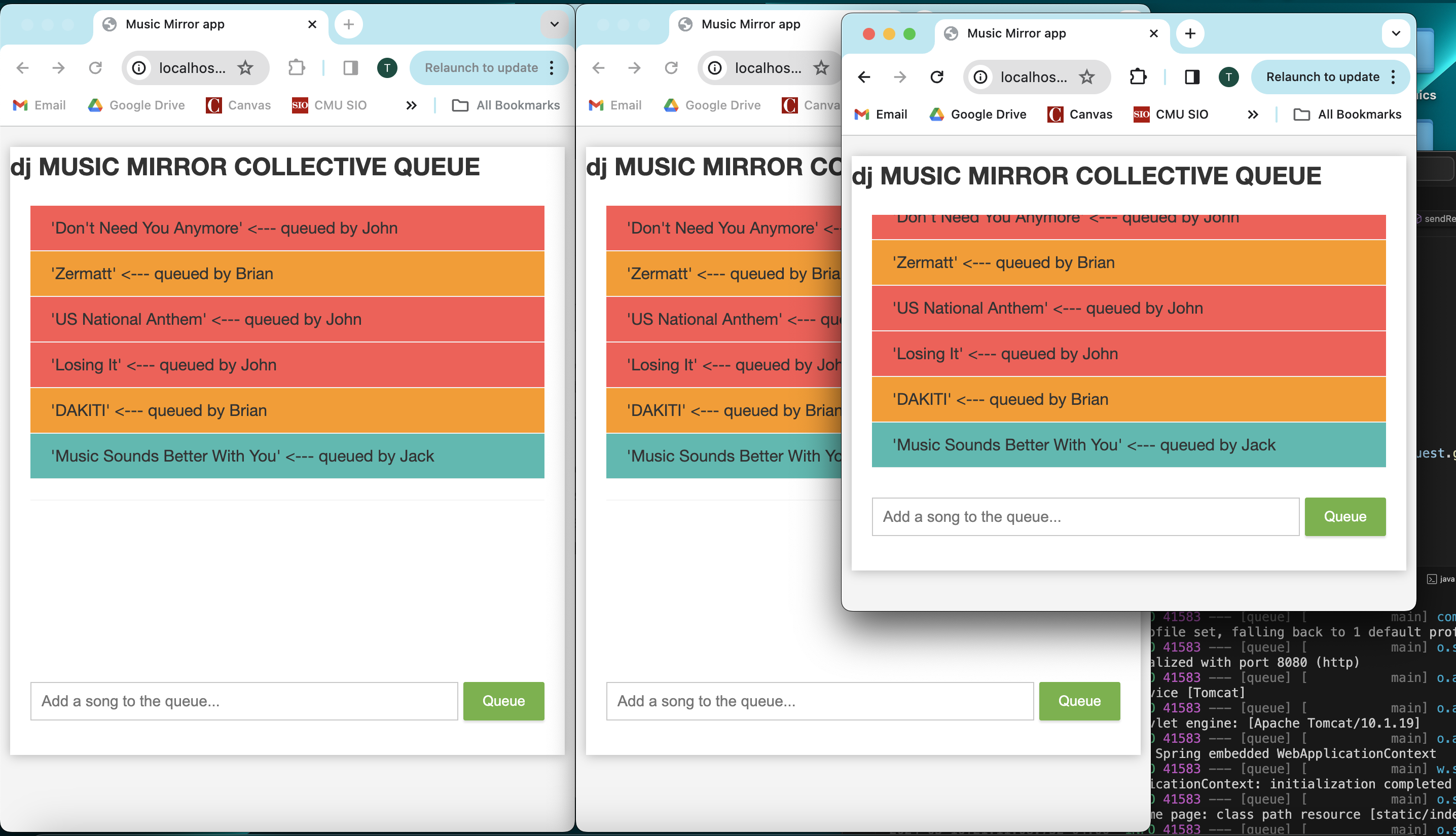
This new Java backend (and tweaked frontend for cleaner queue display) will cooperate nicely with our Spotify semantic match and bluetooth ‘Play’ functionality, as each successive song can be popped off the queue and their song details can be used to find a match and be played from the Spotify song database. The Song datastructure managed by the queue hosted on the backend will contain all the information necessary to generate a query to the Spotify Web API. - Our group is making very good progress on schedule. This week were able to implement much of the fundamental functionality of the project, and now every major component of our project (besides the lighting, as the lighting fixtures we ordered just arrived at the end of this week) is well fleshed out.
- In the upcoming week we hope to finish or make significant progress in integrating our modules together. More specifically, we want our Web App backend to be able to communicate which songs are on the queue to our Spotify Web API facing Player modules to actually play them on the speaker. Additionally, we will do a quick sanity check on the lighting fixture to make sure the DmxPy library is capable of controlling the lighting off the Raspberry Pi, and perhaps begin writing a few of the color scheme scripts we will be running on it.
Luke’s Status Report for 03/16/24
Well, I did a lot of coding this week. I did a lot of work to integrate all of the submodules I’ve been working on into a full pipeline. Now, I am happy to say that the system can go from any song request by name and artist -> to beginning playback of that song on any connected speaker to our wifi streamer. This is huge progress and puts us in a great spot to continue working towards our interim demo. In addition to this, I created the pipeline to go from a song recommendation request to playing the resulting request on the speaker, streamed from Spotify. I will explain these two pipelines and the submodules that they use to get a sense for the work I put into this.
Recommendation:

As seen above, using the SeedGenerator I’ve discussed in previous posts, a recommendation seed is created, fed to the model, which then returns recommended songs that match this seed. This includes their song IDs, which then is used to send an add to queue request and start playback request to the spotify player. The Web API, then uses Spotify Connect to stream the resulting song via wifi to our WiiM music streamer, which then connects via aux to an output speaker. This full pipeline allows us to make a recommendation request, and have this result begin to play on the speaker with no human interaction. It’s awesome. I can’t wait to work on the model with further ideas that I’ve mentioned in previous write-ups and the design report.
Queue by Song/Artist:
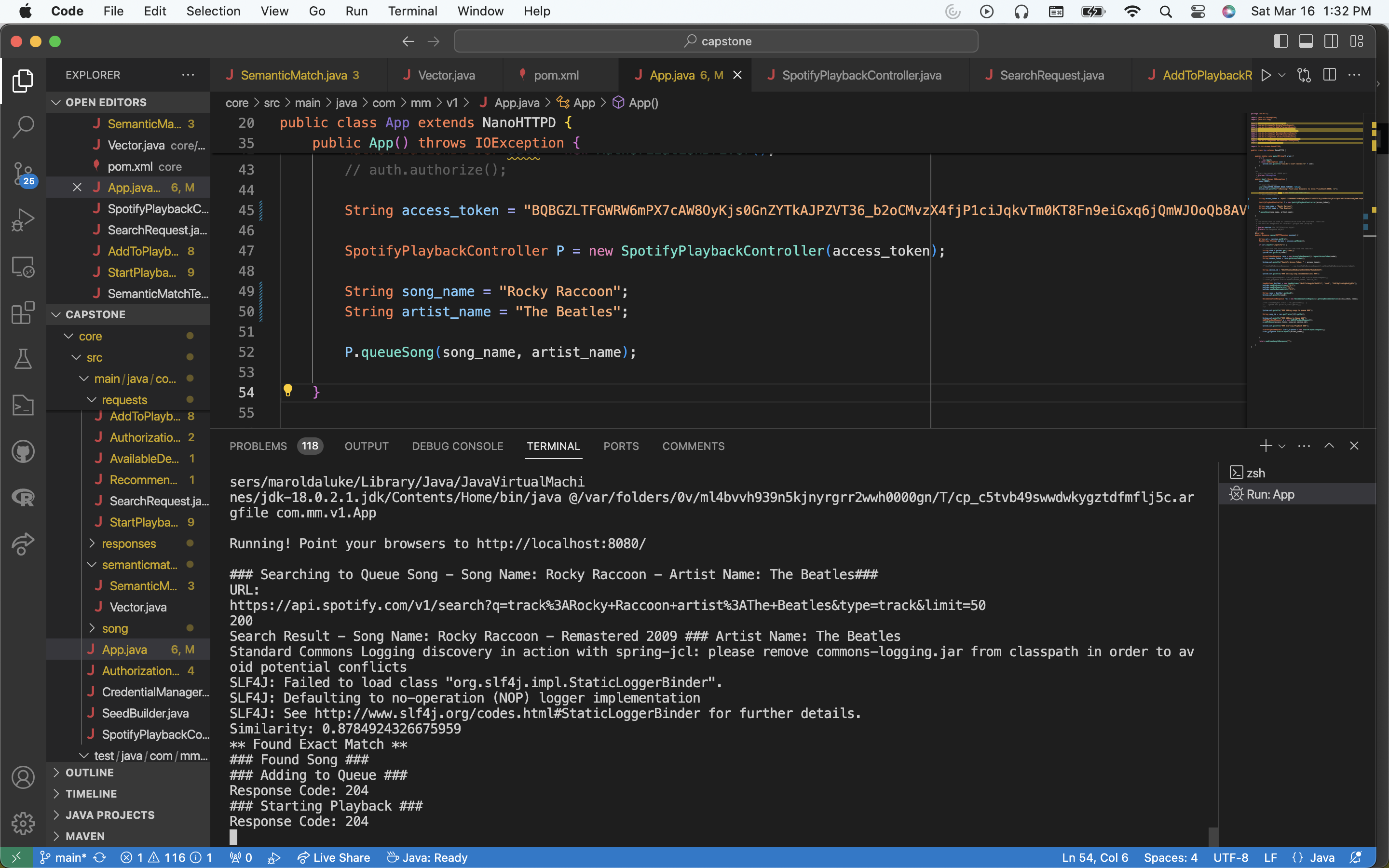
This workflow is the one I am more excited about, because it uses the semantic match model I’ve been discussing. Here’s how it works. You can give any request to queue by providing a song name and the corresponding artist. Keep in mind that this can include misspellings to some degree. This song name and artist combination is then encoded into a Spotify API search request, which provides song results that resemble the request as close as possible. I then iterate thru these results, and for each result, use its song name and artist name to construct a string combining the two. So now imagine that we have two strings: “song_request_name : song_request_artist” and “search_result_song_name : search_result_artist”. Now, using the MiniLM-L6 transformer model, I map these strings to embedding vectors, and then compute the cosine similarity between these resulting embeddings. Then, if the cosine similarity meets a certain threshold (between 0.85-0.90), I determine that the search result correctly matches the user input. Then, I grab the song_id from this result, and queue the song just as described before in the recommendation system. Doing this has prompted more ideas. For one, I basically have 3 different functional cosine similarity computations that I have been comparing results between: one using the embedding model I described, another using full words as tokens and then constructing frequency maps of the words, and lastly using a 1-gram token, meaning I basically take a frequency map character by character to create the vectors, and then use cosine similarity on that. The embedding model is the most robust, but the 1-gram token also has fantastic performance and may be worth using over the embedding because it is so light weight. Another thing I have been exploring is using hamming distance.
This is really good progress ahead of the demo. The next step is to continue to integrate all of these parts within the context of the broader system. Immediately, I will be working further on the recommendation system and build the sampling module to weight the parameters used to generate the recommendation seed.
In all, the team is in a good spot and this has been a great week for us in terms of progress towards our MVP.
Team Status Report for 3/9/24
- Since we all worked on the design presentation for most of our allotted time, we did not make much progress on our actual project. So our risks are the same as last week:
The most significant risks that could jeopardize the success of the project have not changed much so far. More specifically, the first biggest risk is not being able to properly compile and run code for controlling our light fixture automatically through our control program, which would use Flask, Python, and the Open Light Architecture framework to transmit DMX signals to the lighting system. Our concerns are due to comments given on other people’s projects attempting to control lights using the DMX protocol that the OLA framework is a little finicky and difficult to bootstrap, even though after initial setup progress should be smooth and predictable. To mitigate this risk we will be testing our setup before committing completely to OLA. Secondly, another major risk would be not being able to maintain and reason about the different websockets our Users would connect to our DJ system through, as maintaining this live User network is a big part of our use-case. We are mitigating this risk by building these modules early. Finally, the last major concern would be making good persistent programs that thread well on the RPi’s without crashing, as we want our DJ to have near 100% uptime, as we consider even a brief stop in the music playing a fatal error. We can mitigate this risk by researching more into robust microservice programming.
- We changed the web app so that it all is within one of our Raspberry Pis as opposed to the front end being outside of it. This is because we found an existing web socket implementation that contains both the front and back ends. There are no costs associated with this change, just a different way to implement the app. `
- The schedule has not changed significantly.
Part A was written by Luke Marolda, part B was written by Matt Hegi, part C was written by Thomas Lee
A: Users interact with our system through the web app, which could have different availability at different global areas. For example, in the US we are very used to having readily accessible internet that would be used to connect to our system. However, it is important to keep in mind that limited access to the web could be an issue for our users, since they would not be able to interact with our system otherwise. Nonetheless, as long as a user has an internet connection they can use our system – there is no discrimination between those who may be tech savvy and those who are not. A core requisite of our web app is easy use and onboarding, which means there is no prerequisite knowledge needed to participate in the music mirror protocol. Further, our system allows people with different music experience levels to interact, primarily due to the voting system. With the ability to veto songs, as well as like or dislike songs that have been played, it lets users who may not know may songs to recommend still be able to convey their opinion, simply by commenting on what they have heard during the event. This allows opinions to be conveyed even without actually requesting specific songs of your own. Lastly, the system is designed to engage multiple senses from our users – both visual and audio. Therefore, for those who may have a preference between the two, there is still room to enjoy the use of the system.
B: Our project lets guests have a say in what songs are played without going out of their cultural comfort zone. This is because they can add or vote against songs anonomously from their phone. So unless it is culturally not allowed to be on your phone for short periods of time throughout the wedding, everyone can do whatever they are comfortable with / what their cultural rules expect of them. Our project also promotes cultural diversity with our democratic system. Everyone gets a chance to easily nominate a song, so the more diverse the crowd then the more diverse the music will also be.
C: This smart automated DJ project will meet the specified need of being cognizant of environmental factors. Due to the specific operational niche and function of the device there will be two primary environmental sectors impacted. The first would be that of the source and volume of energy necessary to power Music Mirror, and the second would be the holistic and health impacts of the device on living things in its operating radius. For the former, our group must ensure that the device operates with electric power instead of wasteful fossil fuels, and that the amount of power required does not far exceed that of other common medium-sized device rigs, in order to prevent disproportionately adverse effects on the environment and climate. For the later, we must ensure that the volume produced by Music Mirror is not louder than is healthy for human beings (essentially be quieter or comparable to a common nightclub speaker setup) and nearby wildlife, as well as have relatively short ranged lights that do not affect birds, airline pilots, etc. outside of the main event radius.
Thomas’ Status Report for 3/9/24
Thomas Lee
- The week preceding spring break I looked more into the lighting fixture control program leveraging DmxPy. I conversed with a previous ECE capstone group that also used Spotify Web API data to categorize the different genre/moods/types of songs and transmit different control scheme DMX signals to operate the lighting devices. I also spent a considerable amount of time starting the skeleton, writing content for, and organizing the team to efficiently finish the design review report.
- Progress is on schedule
- The next week I will finalize the lighting fixture choice and begin writing a basic control script as a proof of concept, and help make the main RPi backend microservices for accepting user requests and issuing play API calls to the Spotify Web API.
Luke’s Status Report for 03/09/24
This week, I spent my time on a variety of different tasks. Primarily, I worked with my group to complete our design review report. We spent a lot of time finalizing design decisions and trying to convey these decisions in the most accurate and concise way possible. However, a lot of this work was just writing the report so I won’t go into it in too much depth for this report.
Onto the more interesting stuff, I spent some time thinking about ways our recommendation model can outperform Spotify’s vanilla model. The big takeaway from this was essentially using Spotify as a backbone model, but then introducing a second tier to the model which more carefully generates seeds to feed into the rec endpoint. Basically, the Spotify rec model takes in a “seed” to generate a rec, which consists of a bunch of different parameters such as song name, artist, or more nuanced concepts like tone, BPM, or energy level. So, how to construct this seed becomes just as important as the actual model itself. With that being said, I decided on the idea to sample the parameters for this seed generation using our real-time user feedback. This includes user’s thumbs up or thumbs down feedbacks on the songs in the queue via the web app, which gives an accurate representation on how to weight songs based on how much the audience is enjoying them. For example, if a user wants a song similar to the ones that have been played, we can choose which songs to use in this seed generation based on the feedback received by the users. More technically, we can have a weighted average of the song params where the most emphasis is placed on the most liked songs. I will continue to flush out these concepts and actually implement them in code in the coming week.
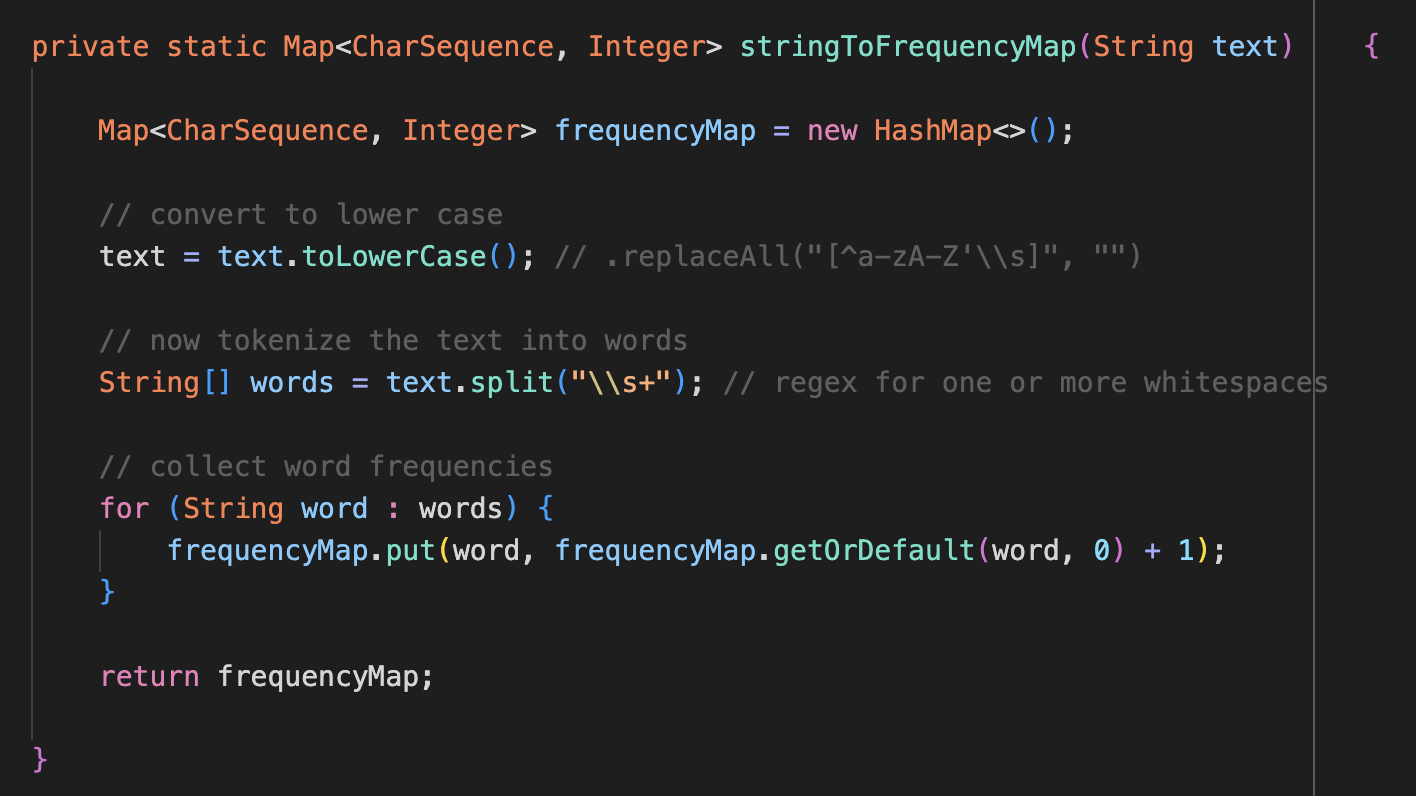
Additionally, I spent time this week on the semantic match algorithm, which is pretty critical for being able to find songs from Spotify’s web API resources. Basically, I implemented cosine similarity between two strings constructed by a song name, its artist, and its album. For example, if a user requested Come Together by the Beatles, which is in Abbey Road, the string that would be used is “Come Together The Beatles Abbey Road”. And that way, we can compare this with a search result such as “Come Together (Remastered) The Beatles Abbey Road” or “Come Together The Beatles Best of the Beatles”.

I won’t get too much into the technical terms but we basically construct vectors of the word frequencies in these input strings, and then find the dot product of the vectors normalize by their lengths. Here is some code and results. Below is how we create the frequency map for the input strings
Now here are some examples. Note that a value of 1 represents maximum similarity
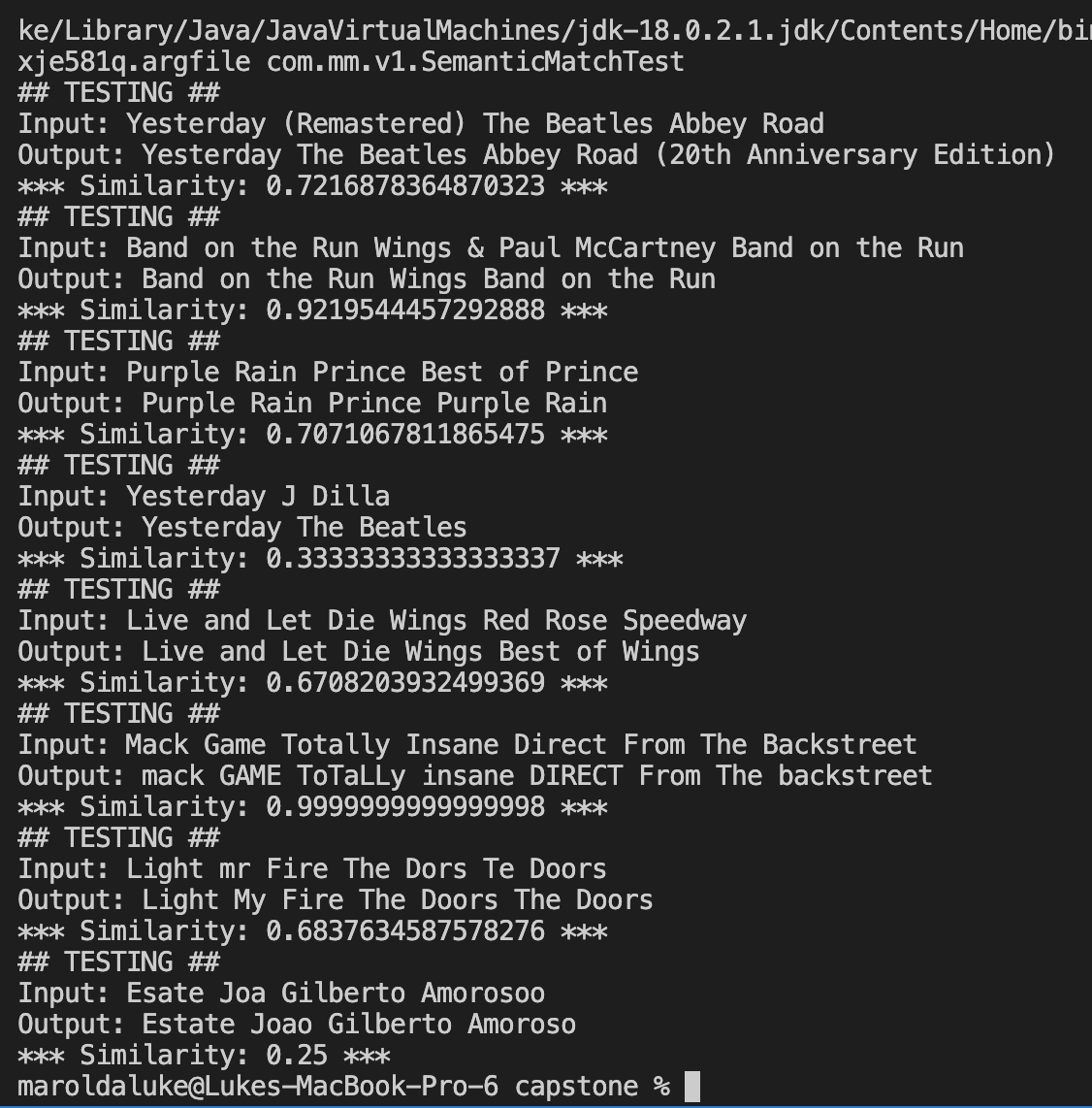
This accuracy should be usable for our purposes, however, I want to improve it. Because I am tokenizing by full words, it is not as accurate at detecting typos and one or two character mistakes by a user, which is illustrated in the last example. Ideally, we want to be more robust to this.
In terms of schedule, we are in a great spot but we have a lot of coding and work to do this week. Now that the design doc stuff is done, we can focus a lot more on actually implementing our ideas.
Next week, I will continue with the semantic match, ML model, and will complete the pipeline between Spotify Connect and a wifi-connected speaker so we can actually play music via an API call.
Matt’s Status Report for 3/9/2024
- The week before break, my first task was to find a way to get the web sockets to work. The whole web app is now running on the Raspberry Pi and multiple users can now connect on the same local network which is what we want. The rest of my time was spent working on the design report.
- My progress is on schedule.
- Next week I want to first try and get the two Raspberry Pi’s talking to each other, then work on more of the backend for our main Pi (the one that keeps track of the users and their songs).
Matt’s Status Report for 2/24/2024
- I started this week by helping prepare our Design Presentation. I made the wireframes for our website and also defined the protocol for how the front end will talk to the Raspberry PI. My main task for this week was to try and establish a WebSocket connection between a Raspberry Pi and a front-end client. I tried a few different things and none of them worked. I will continue to try and figure that out.
- I think my progress is a little delayed since I was not able to get the client and Pi talking this week, but nothing to be concerned about. I will try to finish this as soon as possible so I can get on to next week’s task which I have more experience in.
- Next week I want to first get the WebSocket connection working. After that, I want to make the queuing system work on the backend for one client. I will also be allocating a lot of time for the design report.
Team Status Report for 2/24/24
- The most significant risks that could jeopardize the success of the project have not changed much so far. More specifically, the first biggest risk is not being able to properly compile and run code for controlling our light fixture automatically through our control program, which would use Flask, Python, and the Open Light Architecture framework to transmit DMX signals to the lighting system. Our concerns are due to comments given on other people’s projects attempting to control lights using the DMX protocol that the OLA framework is a little finicky and difficult to bootstrap, even though after initial setup progress should be smooth and predictable. To mitigate this risk we will be testing our setup before committing completely to OLA. Secondly, another major risk would be not being able to maintain and reason about the different websockets our Users would connect to our DJ system through, as maintaining this live User network is a big part of our use-case. We are mitigating this risk by building these modules early. Finally, the last major concern would be making good persistent programs that thread well on the RPi’s without crashing, as we want our DJ to have near 100% uptime, as we consider even a brief stop in the music playing a fatal error. We can mitigate this risk by researching more into robust microservice programming.
- As we just recently gave the Design Presentation, within that presentation was our most up-to-date system design, and there were no changes made to our system design after that.
- The schedule has not changed significantly.