Well, I did a lot of coding this week. I did a lot of work to integrate all of the submodules I’ve been working on into a full pipeline. Now, I am happy to say that the system can go from any song request by name and artist -> to beginning playback of that song on any connected speaker to our wifi streamer. This is huge progress and puts us in a great spot to continue working towards our interim demo. In addition to this, I created the pipeline to go from a song recommendation request to playing the resulting request on the speaker, streamed from Spotify. I will explain these two pipelines and the submodules that they use to get a sense for the work I put into this.
Recommendation:

As seen above, using the SeedGenerator I’ve discussed in previous posts, a recommendation seed is created, fed to the model, which then returns recommended songs that match this seed. This includes their song IDs, which then is used to send an add to queue request and start playback request to the spotify player. The Web API, then uses Spotify Connect to stream the resulting song via wifi to our WiiM music streamer, which then connects via aux to an output speaker. This full pipeline allows us to make a recommendation request, and have this result begin to play on the speaker with no human interaction. It’s awesome. I can’t wait to work on the model with further ideas that I’ve mentioned in previous write-ups and the design report.
Queue by Song/Artist:
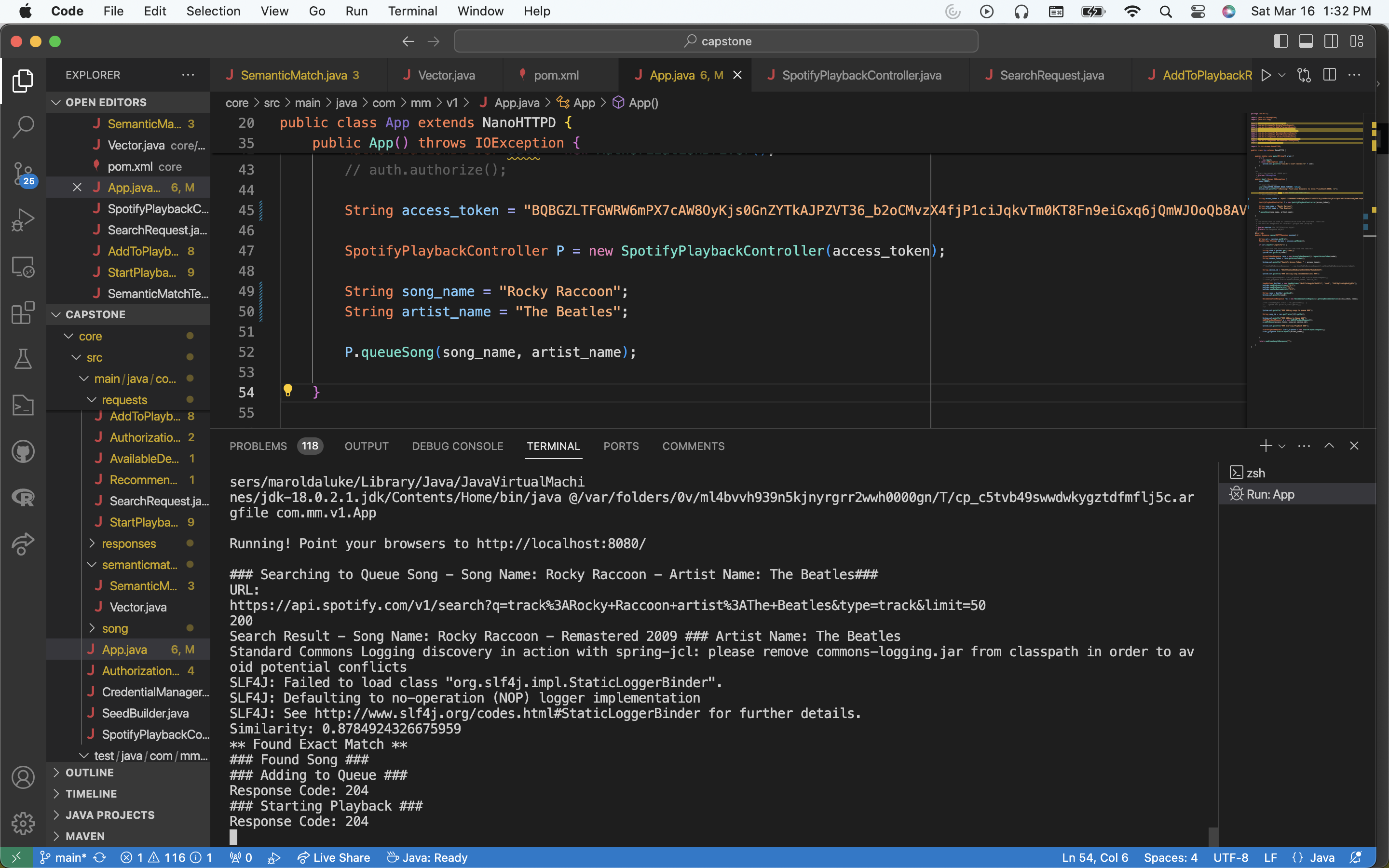
This workflow is the one I am more excited about, because it uses the semantic match model I’ve been discussing. Here’s how it works. You can give any request to queue by providing a song name and the corresponding artist. Keep in mind that this can include misspellings to some degree. This song name and artist combination is then encoded into a Spotify API search request, which provides song results that resemble the request as close as possible. I then iterate thru these results, and for each result, use its song name and artist name to construct a string combining the two. So now imagine that we have two strings: “song_request_name : song_request_artist” and “search_result_song_name : search_result_artist”. Now, using the MiniLM-L6 transformer model, I map these strings to embedding vectors, and then compute the cosine similarity between these resulting embeddings. Then, if the cosine similarity meets a certain threshold (between 0.85-0.90), I determine that the search result correctly matches the user input. Then, I grab the song_id from this result, and queue the song just as described before in the recommendation system. Doing this has prompted more ideas. For one, I basically have 3 different functional cosine similarity computations that I have been comparing results between: one using the embedding model I described, another using full words as tokens and then constructing frequency maps of the words, and lastly using a 1-gram token, meaning I basically take a frequency map character by character to create the vectors, and then use cosine similarity on that. The embedding model is the most robust, but the 1-gram token also has fantastic performance and may be worth using over the embedding because it is so light weight. Another thing I have been exploring is using hamming distance.
This is really good progress ahead of the demo. The next step is to continue to integrate all of these parts within the context of the broader system. Immediately, I will be working further on the recommendation system and build the sampling module to weight the parameters used to generate the recommendation seed.
In all, the team is in a good spot and this has been a great week for us in terms of progress towards our MVP.