This week, I spent my time on a variety of different tasks. Primarily, I worked with my group to complete our design review report. We spent a lot of time finalizing design decisions and trying to convey these decisions in the most accurate and concise way possible. However, a lot of this work was just writing the report so I won’t go into it in too much depth for this report.
Onto the more interesting stuff, I spent some time thinking about ways our recommendation model can outperform Spotify’s vanilla model. The big takeaway from this was essentially using Spotify as a backbone model, but then introducing a second tier to the model which more carefully generates seeds to feed into the rec endpoint. Basically, the Spotify rec model takes in a “seed” to generate a rec, which consists of a bunch of different parameters such as song name, artist, or more nuanced concepts like tone, BPM, or energy level. So, how to construct this seed becomes just as important as the actual model itself. With that being said, I decided on the idea to sample the parameters for this seed generation using our real-time user feedback. This includes user’s thumbs up or thumbs down feedbacks on the songs in the queue via the web app, which gives an accurate representation on how to weight songs based on how much the audience is enjoying them. For example, if a user wants a song similar to the ones that have been played, we can choose which songs to use in this seed generation based on the feedback received by the users. More technically, we can have a weighted average of the song params where the most emphasis is placed on the most liked songs. I will continue to flush out these concepts and actually implement them in code in the coming week.
Additionally, I spent time this week on the semantic match algorithm, which is pretty critical for being able to find songs from Spotify’s web API resources. Basically, I implemented cosine similarity between two strings constructed by a song name, its artist, and its album. For example, if a user requested Come Together by the Beatles, which is in Abbey Road, the string that would be used is “Come Together The Beatles Abbey Road”. And that way, we can compare this with a search result such as “Come Together (Remastered) The Beatles Abbey Road” or “Come Together The Beatles Best of the Beatles”.

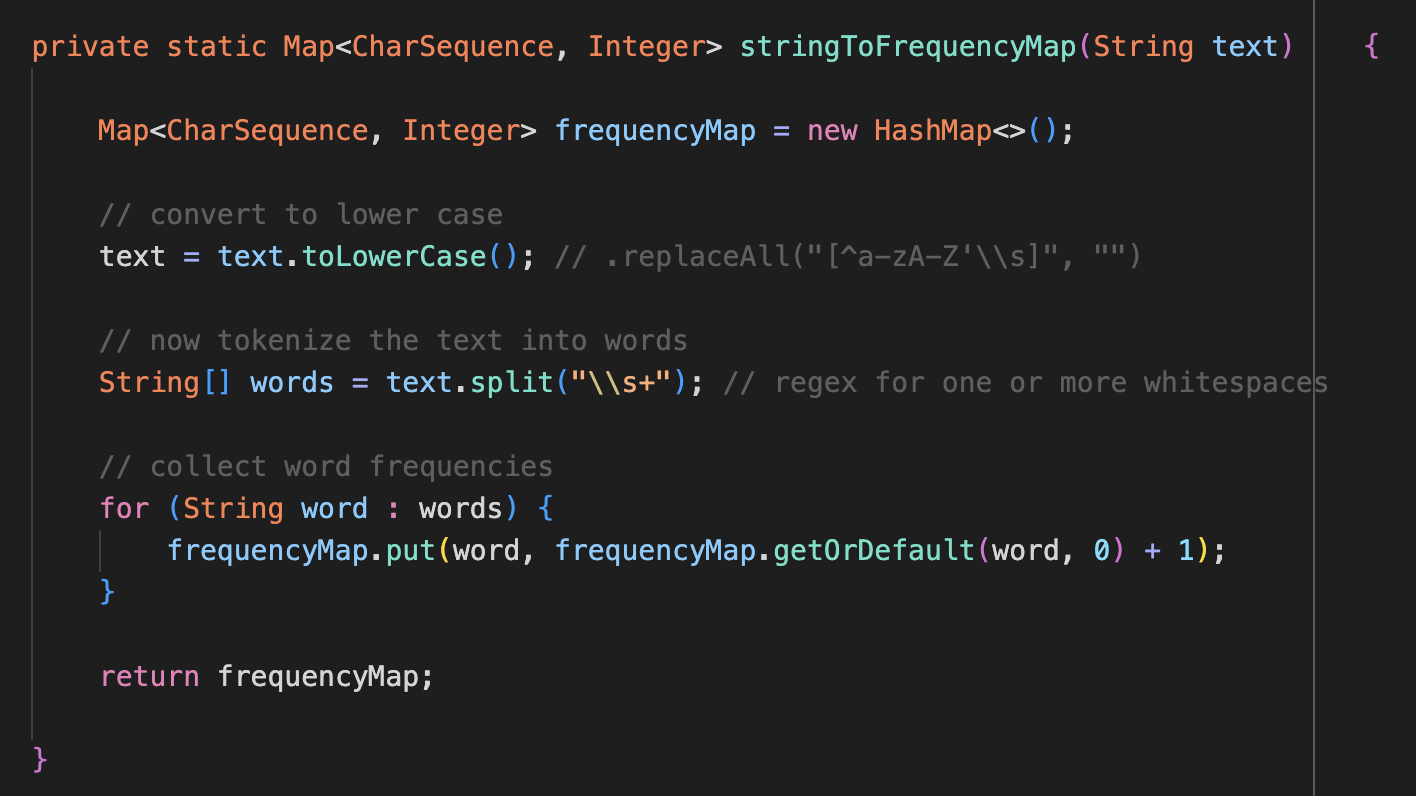
I won’t get too much into the technical terms but we basically construct vectors of the word frequencies in these input strings, and then find the dot product of the vectors normalize by their lengths. Here is some code and results. Below is how we create the frequency map for the input strings
Now here are some examples. Note that a value of 1 represents maximum similarity
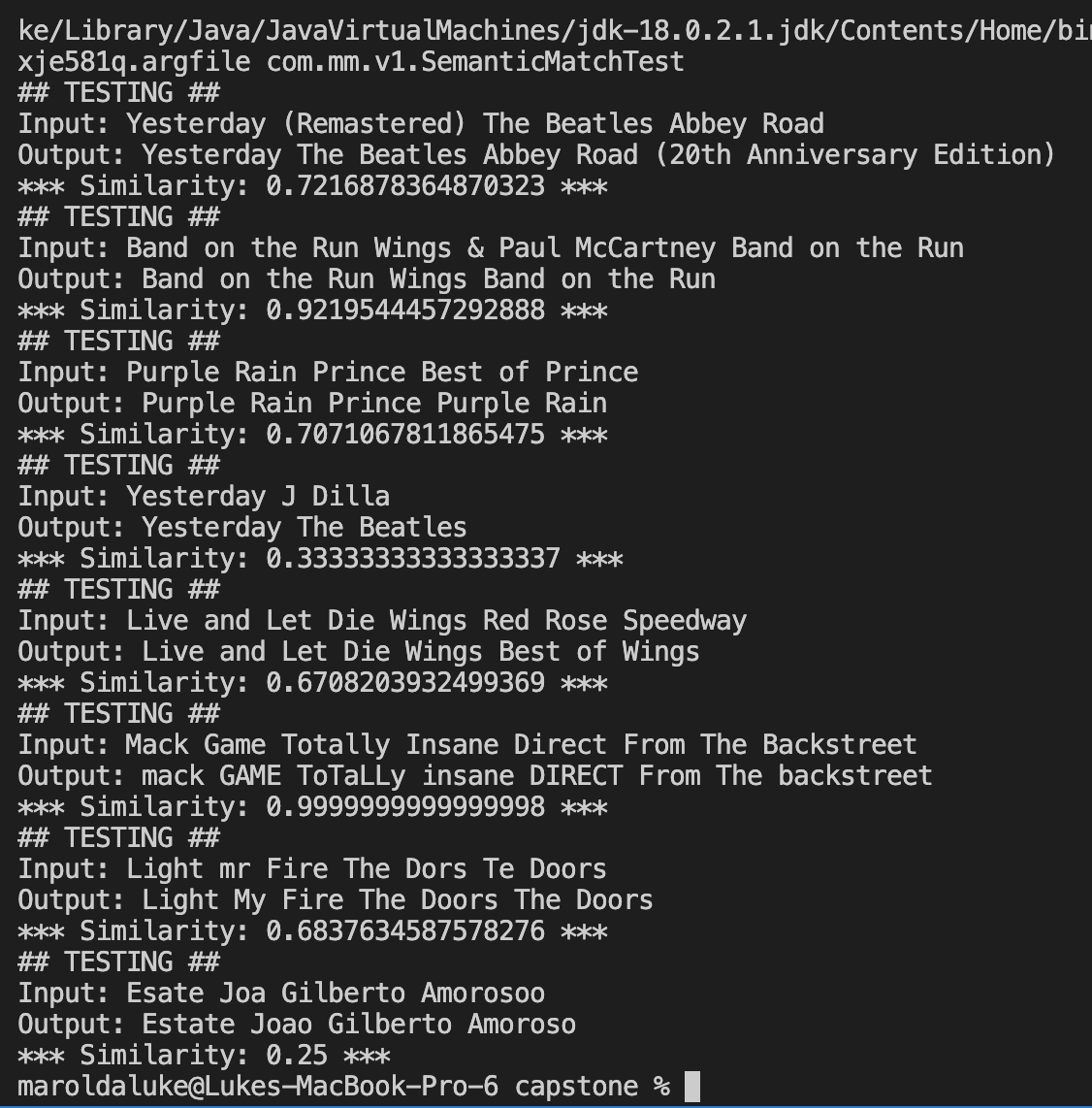
This accuracy should be usable for our purposes, however, I want to improve it. Because I am tokenizing by full words, it is not as accurate at detecting typos and one or two character mistakes by a user, which is illustrated in the last example. Ideally, we want to be more robust to this.
In terms of schedule, we are in a great spot but we have a lot of coding and work to do this week. Now that the design doc stuff is done, we can focus a lot more on actually implementing our ideas.
Next week, I will continue with the semantic match, ML model, and will complete the pipeline between Spotify Connect and a wifi-connected speaker so we can actually play music via an API call.