Personal accomplishments
After a lot of deliberation,we decided to remove certain features that were not affecting our audio signals as much. I thought alot about the use of MFCC as well, and I don’t think that was adding as much value as isolating frequencies. So, the newer approach to chunk these dataframes is to use peak frequencies, beat detection, and amplitudes. We also thought about isolating parts of the chorus, but quickly realized that amplitudes are reflective of While combining these with global parameters, we can see that this gives us quite a bit of information to work off of. This was a necessary reduction in the number of features because we were getting a bit of relevant information. We also increased the resolution of the graphs to incorporate values from every 10th of a second. This made our existing graphs very dense. This is to account for the beats for most popular tempos that occur around 6 times per second. To make all our chunks consistent size and dimensions, we needed to increase resolution to 1/10th of a second. I tried out functions librosa.piptrack to enable pitch detection but there are too many 0s in my arrays, and these null values don’t come from my padding either. I am looking into fundamental frequencies using librosa.pyin instead as this might give me a spectrogram of consistent frequencies. I decided to go with a CQT spectrogram to get frequency bins to better reflect the prominent scales in the audio signal.
To solve the issue of getting denser information for some attributes, and getting less dense information, I decided to just see if I could get enough values mapped for a single second. I am able to generate a few log files for amplitudes, beat detection for an audio file, get prominent frequency bins, and get the global params (spotify features) for a particular song. I split the harmonic and percussive parts to get the voiced and unvoiced to get more dynamic audio for lighting. Looking at a few lighting shows, they emphasized making the lighting more prominent during the voiced parts of the audio, and reducing it for a few parts of the unvoiced parts.
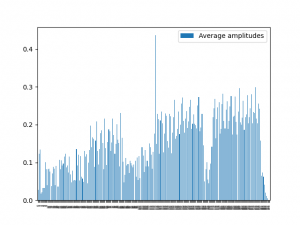
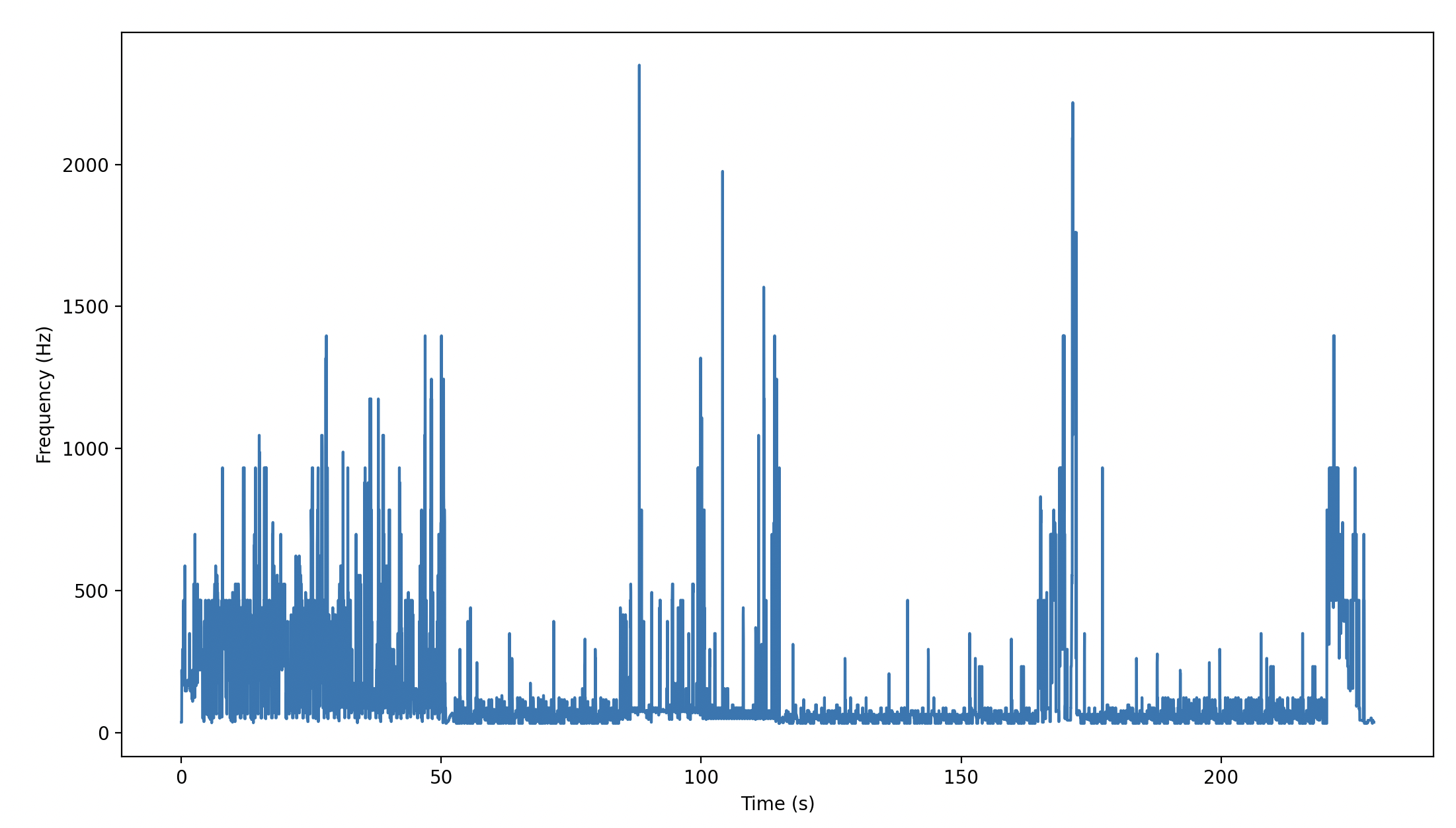
On Track?
I think we are decently on track with stuff. I might have to make changes on the signal processing parameters depending on more songs I test with. I have only tested with Teenage Dream, and an increasing frequency of audio. So, tomorrow as we test with the interim demo, we might have to make changes to the signal processing parameters as we go. Currently we are going over the integration logic to map signal parameters, and spotify parameters to lighting calls. We hope to have a few calls mapped and test ready for the interim demo
Goals for next week
We are trying to have a few sample files that map audio params to lighting calls, and through some ways in which we are able to control one variable, we are seeing a difference in lighting. There is a lot of complexity in trying to mash parameters the best way possible to see lighting changes that we can expect.