This week, we focused on integration and testing, and I also made some minor improvements to the CV algorithm, and attempted to collect more data for training.
Integration with Jetson
The Jetson was surprisingly annoying and difficult to setup, and I spent at least 10 hours just trying to get my CV code to run properly on the Jetson. In particular, trying to install various dependencies like PyTorch and OpenCV took a long time; we needed to compile a lot of dependencies from source (which came with a lot of its own errors) because the Jetson is an ARM aarch64 system which is not compatible with the x86_64 architectures that most things are precompiled for. The various issues were compounded by the fact that the Jetson was slightly old (using older version of Ubuntu, low RAM and memory capacity).
Even after I/we* managed to get the code up and running on the Jetson, we had significant problems with the speed of the Jetson system. I/we at first tried various methods including turning off visual displays and killing processes. Eventually, we realized that the bottleneck was … RAM!!!
What we discovered was that the Jetson took 1-2 minutes to make its first prediction, but then ran relatively quickly (~135ms) after that. This is in comparison to my computer which runs a single prediction in ~30ms. When Alex was debugging with a display of system resources, we eventually pinpointed the issue to being the lack of sufficient RAM when loading and using the model for the first time: the model was just too big to fit into RAM properly, and a major bottleneck came from having to move some of that memory into SWAP. Once that was complete, the algorithm ran relatively quickly. However, because it is nonetheless using memory accesses (swap) instead of the faster RAM, the predictions on the Jetson still ran slower than that of my computer. Nonetheless, it still runs fast enough (~135ms) after this initial “booting” stage, which has now been integrated as part of the “loading” in my CV code.
*while I was in charge/did most of the debugging, my teammates were also instrumental in helping me get it up and running (it is after all, Alex’s Jetson), so credit should be given where it is due 🙂
CV Training
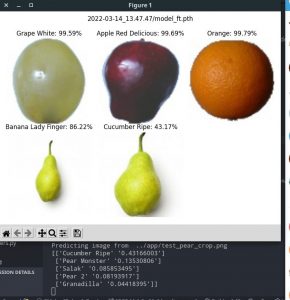
While trying to fix/install dependencies on the Jetson, I had also in parallel attempted to collect some more data with the new fake fruits that came in, including the addition of a new “Lemon” class. However, our model could not converge properly. I believe that it was due to the fact that some of the fake fruits/vegetables were not very high-quality, and looked fairly different from the ones in the original dataset (and in real life) like the peach and pear, so when validating against our original test images, it failed to perform very well. Next week, I aim to try training only the fake fruits/vegetables that look realistic enough (like the apple, lemons and eggplant). That being said, the algorithm already performs very well against some of the semi-realistic fake fruit, like the starfruit and banana shown in Figure 1 below.
During testing, I was actually pleasantly amazed by the neural network’s ability to detect multiple fruits despite being a classifier, and outputting probabilities associated with those fruits. As can be seen in Figure 1 below, the fruits being captured are Apple, Banana and Starfruit, which appear as the top 3 probabilities on the screen, as detected by the network.

Figure 1: Multiple Fruits Detection
Minor Improvements – White Background Detection
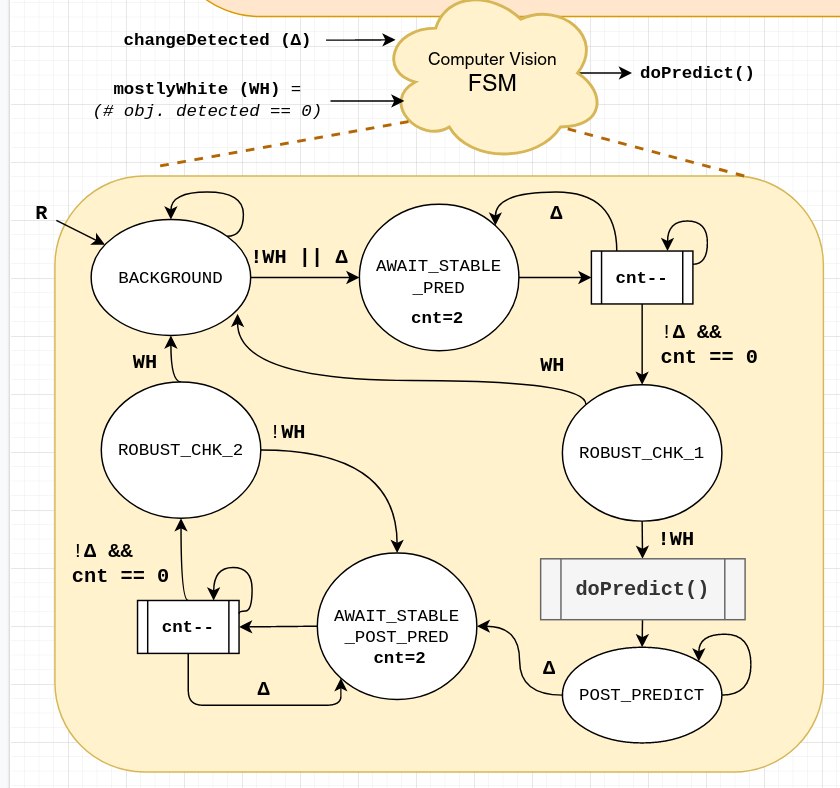
After spray painting the platform with Alex, we now had a good white background to work with. Using this piece of information, I was able to have a simple (and efficient) code that detects whether the background is mostly white using the HSL image representation, and checking for how many pixels are above a certain threshold.
Since my algorithm currently uses changes in motion (i.e. pixel changes between the frames) to switch from different states (background, prediction, wait for user to take off their fruit) in my internal FSM, this white background detection adds an important level of robustness against unforeseen changes, like an accidental hand swipe, lighting changes or extreme jerks to the camera. Otherwise, the CV system might accidentally go into a state that it is not supposed to, such as awaiting fruit removal when there is no fruit there, and confuse/frustrate the user.
Future Work
We are currently far ahead of schedule in terms of what we originally wanted to do (robust CV algorithm, fruit + vegetable detection), but there are a few things left to do/try:
- Quantity detection: This can be done by using white background segmentation (since I already have some basic algorithm for that) + floodfill to have a rough quantity detection of number of fruits on the platform. Right now, our algorithm is robust to multiple fruits, and there is already an API interface for quantity.
- Adding more classes/training: As mentioned above, I could try retraining the model on new classes using the fake fruits/vegetables + perhaps some actual ones from the supermarket. Sadly, my real bell peppers and apple are already inedible at this point 🙁