This week, we worked on the design review slides, and as part of the process, we finalized our designs for the attachment system, CV algorithms, UI interface and backend. Notably, I made a contribution to a new scanner system design, where I suggested making the camera scan overhead onto the platform as opposed to a front-facing camera as originally designed. This will allow for a more intuitive and less intrusive scanning process.
In particular, as the one in charge of the CV algorithm, I wrapped up research on the various algorithms to use for classification. In particular, I decided to go with the ResNet based CNN instead of traditional SURF/SIFT methods because of the better accuracy and performance. I modified the code of this tutorial to train a classifier and was able to successfully train a model that achieved 98% accuracy after 10 epochs.
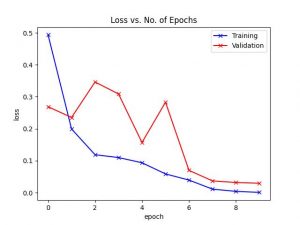
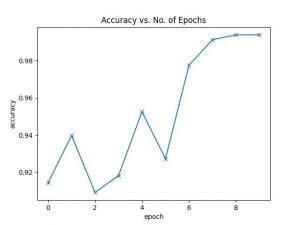
However, it remains to be seen if the classifier will work well with validation data (ie check for overfitting), and especially whether it will work with real-world data (our actual setup) . Next week, I will be working on the C++ PyTorch code to run said trained network, meant for optimized runningon the Jetson. I will also begin working on a basic webcam setup (the webcam just arrived this Wednesday!) and collect real-data images that I can use for testing.