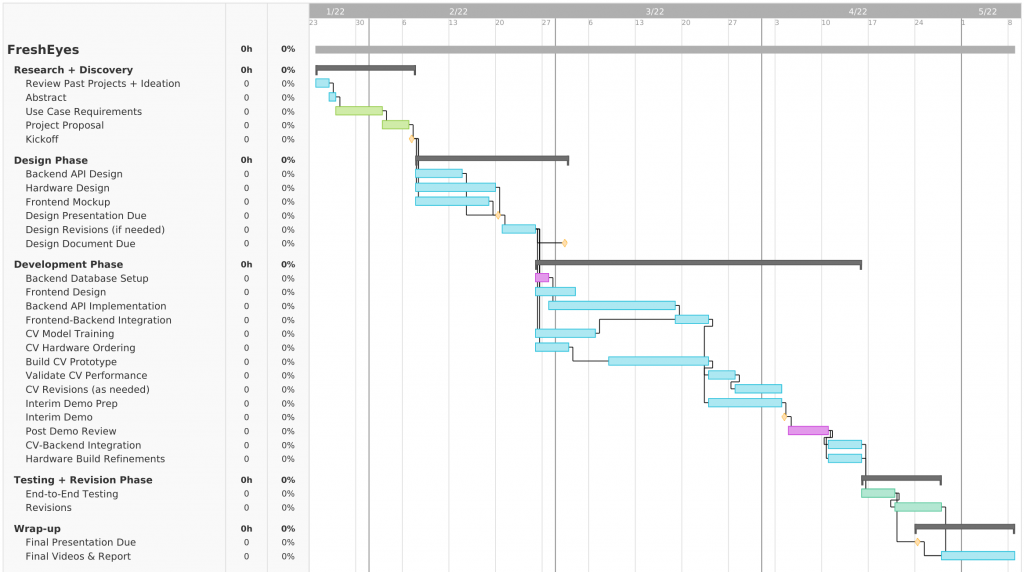
This is the last status report for the project! As we step in finals week, I crafted and presented the final presentation, and the final presentation seems to have turned out well!
The CV system is now also capable of making quantity guesses. I updated the API specification on the backend to support the new capability in order to allow quantity information to be sent from the CV system to the backend, and then to the frontend for display in the confirmation dialog. This required a mini-rewrite of the schema as well as the relevant API endpoints, but it was not too troublesome and I was able to deliver it in just 2 days.
In preparation for the final presentation as well as poster, I updated the overall architecture diagram, and consolidated test results and compared them against our use case requirements. All our explicitly defined use case requirements have been achieved! (see presentation) This is a testament to our good work both individually and as a team.
Coming up, there are some stretch goals and “nice-to-haves” that we can try to implement. Of higher priority is the final report and demo, and with that we will wrap up our project, on time and on schedule!
 The back-end API had quite a bit of work done to it as well. Logic has been added for when items are replaced into the fridge, ensuring that the item count and expiry dates remain correct even when the same item is removed and placed back into the fridge. This is done by storing the state of the fridge – new items are only added to the tally when it is in “add” mode, i.e. when the user is loading new groceries from the store. All other additions in the “track” mode are considered replacements of previous removals.
The back-end API had quite a bit of work done to it as well. Logic has been added for when items are replaced into the fridge, ensuring that the item count and expiry dates remain correct even when the same item is removed and placed back into the fridge. This is done by storing the state of the fridge – new items are only added to the tally when it is in “add” mode, i.e. when the user is loading new groceries from the store. All other additions in the “track” mode are considered replacements of previous removals.