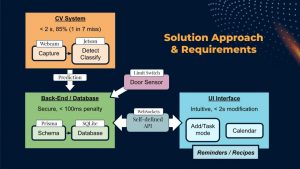
This week, we completed our design review presentation, which we think went quite well. Our main focus for next week will be the design review report, due Wednesday next week. After Wednesday, we will continue working individually on our various responsibilities to implement the CV, UI and back-end systems for Samuel, Alex and Oliver respectively.
Currently, we have made good progress on the implementation side, and are slightly ahead of schedule in this sense (see our individual reports for more information):
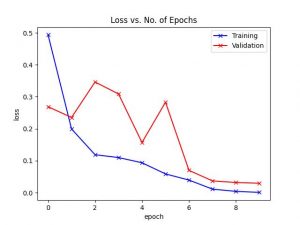
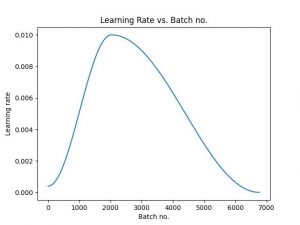
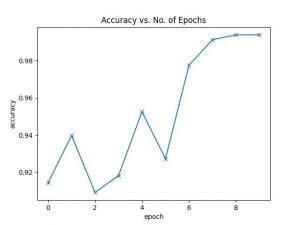
- Samuel: Completed C++ testing for CV. Discovered that the CNN network found from Medium does not work well and has major flaws with the customized architecture. Will begin work next week training and testing a new ResNet18 or AlexNet model.
- Oliver: Enforced a rigorous common standard in the back-end code-base by integrating automatic linting, type-checking, and even bug catching tools. Brought the code-base to strict, 100%, type-safe standards, setting up the back-end for seamless and co-operative development regardless of each team member’s individual style, and ensuring that code pushed meets high levels of rigor. Will deliver a core set of APIs next week built upon this level of rigor for integration with front-end
- Alex: Completed most of basic UI. Will start collaborating with Oliver once API side is complete. Helped Samuel with the training of the classification algorithm