

For the past two weeks, I have worked with Sid collecting a dataset and training different convnets to classify the images.
For training, we have the following data:
Training images: 3481
Validation images: 497
Testing images: 996
The camera returns a 1280×720 image. We crop it to a fixed region-of-interest and downsample by 4 to obtain a 200×148 image. We normalize the training and validation dataset to mean 0 and std 1. That normalized 200×148 image is then passed to the network.
The network architecture is based off on the LeCun-5 network described in LeCun et al., “Gradient-Based Learning Applied to Document Recognition.” It contains 4 convolutional layers with 5×5 kernels, one fully connected layer to output the feature vector, and two separate fully connected layers to output the rank and suit probability distributions. Each convolutional layer is followed by batch normalization and 2×2 max-pooling.
So far, our best network achieves 98.0% validation accuracy and 97.5% test accuracy. A card is classified correctly if both the rank and suit are correct. This network takes approximately 50ms to classify a single image on the Jetson Nano, so we have plenty of headroom to achieve the 2s latency requirement.
Because the PCB is delayed, we are still delayed in testing the images and classification using the final prototype with the PCB. However, Sid and I are on track to hit the 98% accuracy requirement and complete the classification subsystem with our current prototype until the hardware is finished.
Here are details from the training process:
Validation metrics
Card accuracy (suit and rank): 0.979879
Suit accuracy: 0.993964
Rank accuracy: 0.985915
Test metrics
Card accuracy (suit and rank): 0.974900
Suit accuracy: 0.996988
Rank accuracy: 0.976908
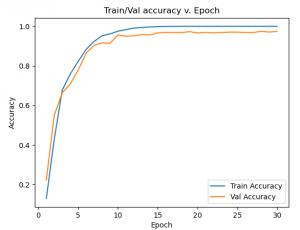
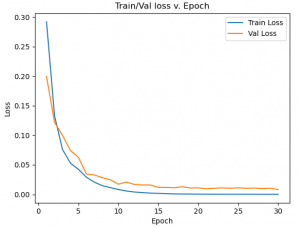
This week, Sid and I will take more training images to increase our dataset size. We can experiment with larger networks with more data to hit 98% test accuracy.