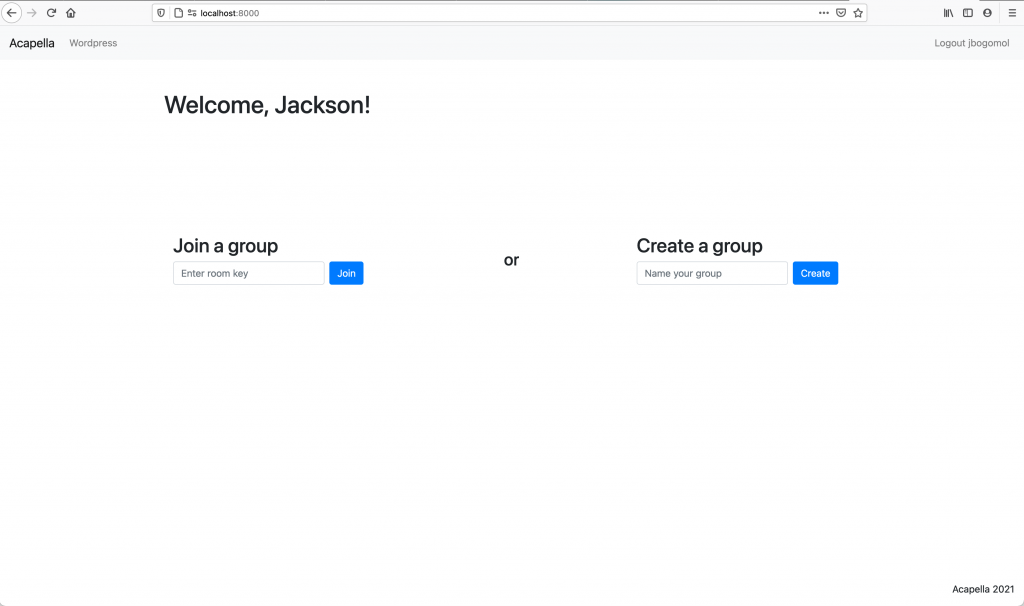
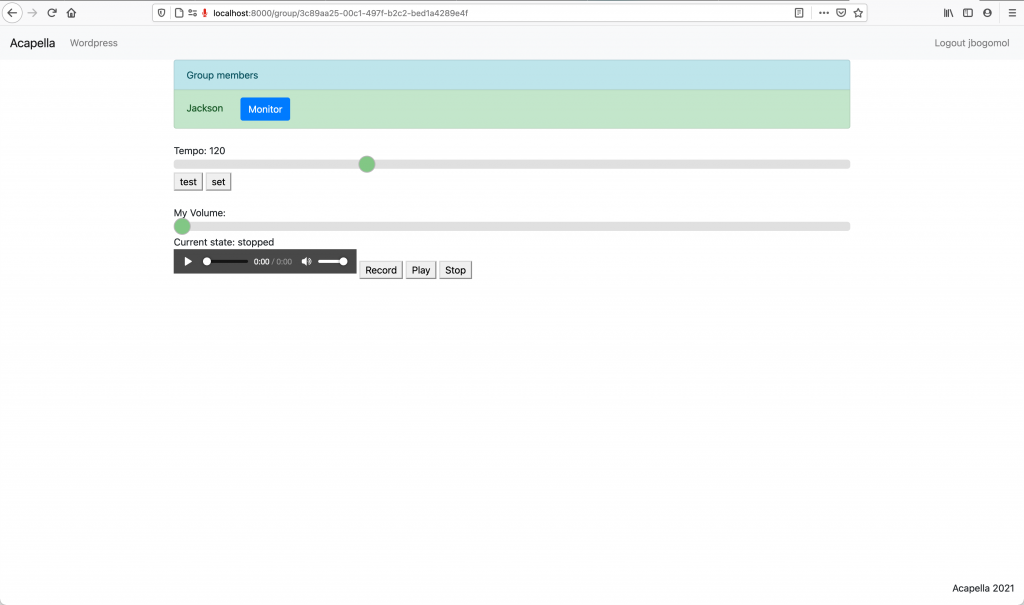
This week, we’ve made a lot of progress on the monitoring aspect of our project. As outlined in Jackson’s status report, websocket connections between each user and the server are working, as well as WebRTC peer-to-peer connections. Though audio is not sent from browser to browser quite yet, simple text messages work just fine, and sending audio will be completed by next week. In addition, the click track is working, and the user interface has seen big improvements.
There are a few major changes to our design this week:
- To allow multiple asynchronous websocket connections open at once, we had to add a Redis server. This runs simultaneously with the Django server, and communicates with the Django server and its database over port 6379. This was based on the tutorial in the channels documentation, though that tutorial uses Docker to run the Redis server, while I just made the Redis server work in a terminal. This change doesn’t have much of a trade off, it’s just a necessary addition to allow asynchronous websocket channels to access the database.
- We have decided to use WebRTC for peer-to-peer connections. In our design review, we planned to use TCP, since it gives a virtually 0% packet loss rate. The cost of using TCP is big though when latency is such an issue as it is with music, making it impractical. WebRTC is used for real-time communication and particularly designed for media streaming between users. It uses UDP to send data with the lowest possible latency, and it’s built in to the user’s browser. The only real cost here is that now we do have to worry about packet loss. But for something like music where timing is so critical, we’ve decided that meeting the latency requirement (<100ms) is far more important than the packet loss requirement (<5%).
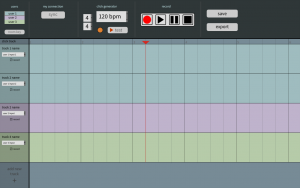
Since the WebRTC connection is working, we no longer have to worry about not having monitoring. However, we do have a number of other big risks. As I see it, our biggest risk right now is that none of us really know how to create the DAW user interface we showcased in our design review. Visualizing audio as you’re recording and being able to edit the way you can in industry DAWs like Pro Tools/Audacity/Ableton/etc. is going to be a challenge. To mitigate this risk, we will need to put extra work into the UI in the coming weeks, and if this fails, we can still expect to have a good low-latency rehearsal tool for musicians even without the editing functionality.