The most significant risk at this point in the semester, since our MVP is complete, is ensuring that our design process is well documented and clear in the final report. We are mitigating this risk by taking the feedback we received during our final presentation and following the final report guidance provided on Canvas. We also made notes of the feedback we received from our midterm report and we will focus on the design trade offs section of the report as these are the primary areas we were asked to improve. For the results section that will be expanded on, based on the notes given to all teams during the final presentations, we shall ensure to include details such as size of datasets, number of trials and equations used for our percentages.
We were able to get our system to work on boot. This required creating a systemd service file to call our python script. Additionally we improved our frames per second by reducing the size of the cv2 frame the Jetson was seeing. No additional changes were made to our software or hardware design.
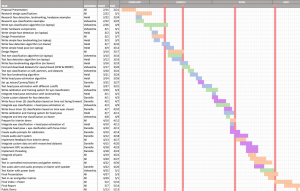
We have no changes to our schedule. We are finishing up the final deliverables of the semester: final video, public demo, poster and report.