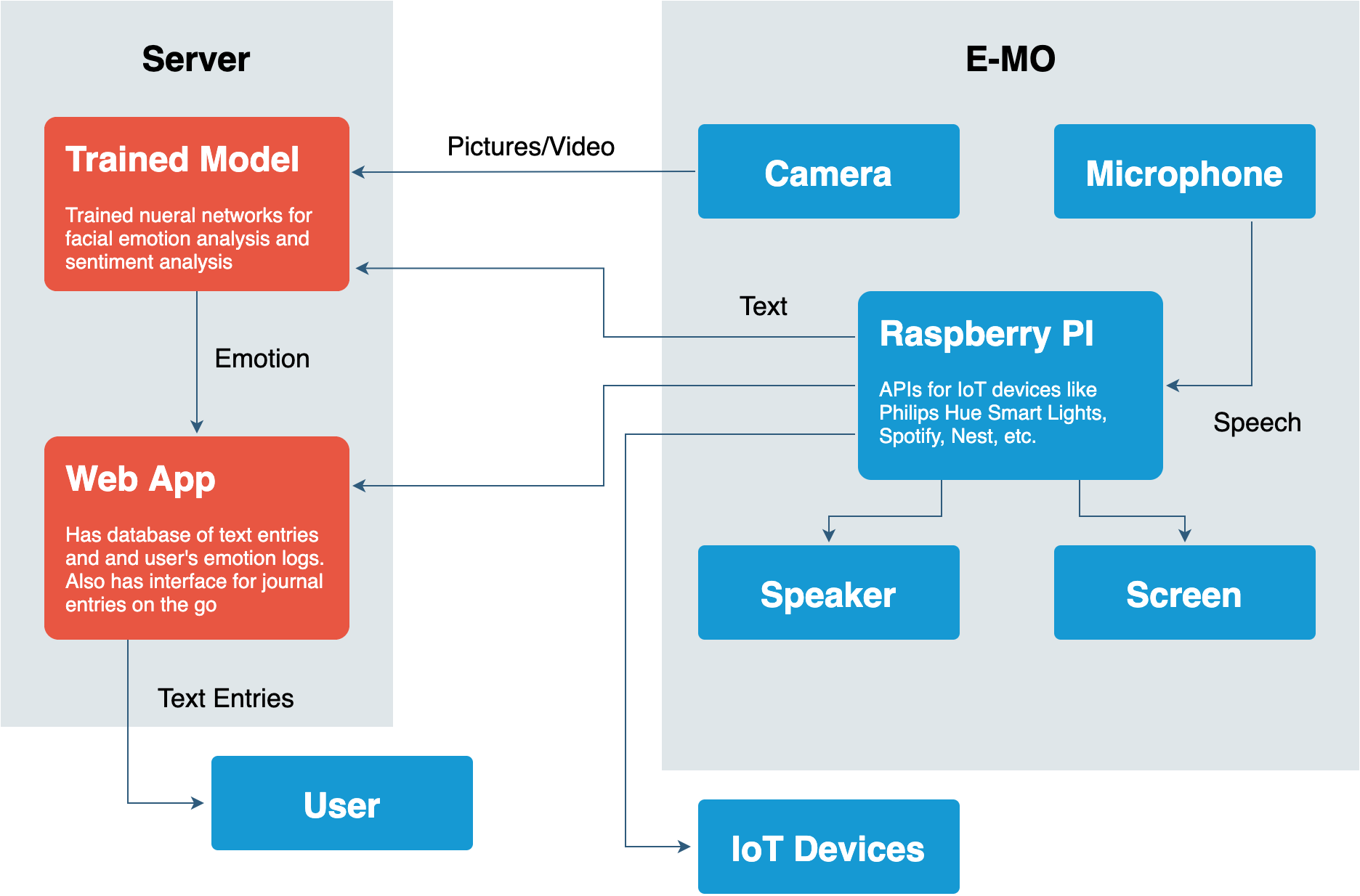
Methods to treat mental illness today are relatively archaic compared to the current technology available. Mental health experts are unable to monitor patients day-to-day unless they are restricted to an institution. We aim to create a robot therapist that can provide daily logging of a patient’s improvement through audio diary entries, which it will then analyze for emotion. The robot would use a combination of speech and facial emotion recognition to analyze the user’s mood and respond by creating a corresponding environment using IoT devices like speakers, lights, and other IoT devices. We would first use Google’s Speech to Text API to figure out what the user said and then use sentiment analysis to extract the emotion from the text. We plan to use Google’s Speech API because training our own speech-to-text algorithm will require too much data to achieve an accuracy even relatively close to the accuracy of Google’s Speech API, and speech-to-text is not the main purpose of our project – just a step to achieve real-time sentiment analysis. At the same time, we would use a pre-trained CNN to extract features from the user’s face, which we will then classify into one of six emotions with our trained SVM. These emotions include happiness, sadness, anger, surprise, disgust, and fear. We plan to train the sentiment analysis using the Sentiment140 dataset and facial emotion recognition networks with the CK+ and AffectNet datasets. Finally, these two evaluations of the user’s sentiment are combined to make one emotion classification which will be used to decide what kind of environment to create for the user. We plan on using the Spotify API to select the appropriate songs to play and smart LED bulbs to set lighting. Spotify has hundreds of playlists, sorted by mood, that can be correlated with the user’s emotion. The sentiment analysis and facial emotion recognition algorithms will be hosted on an AWS instance, with the result being sent back to a Raspberry Pi on the robot. We will create the body of the robot through 3D printing and laser cutting. Current facial emotion recognition technology peaks at around 70-85% accuracy, although real world performance typically had around 50% accuracy. We aim to hit 65% accuracy as our use case involves fewer face angles which are the main detriment to accuracy. Sentiment analysis also peaks at 70-85% accuracy. We aim to hit 65% accuracy since our text is transcribed and lacks major sentiment signs such as emoticons and punctuation. Under the assumption that the two methods of emotion detection will constructively improve our classification accuracy, we aim to have an accuracy of 75% overall. We hope to analyze the user’s face and take action in under 10 seconds assuming a stable connection to the internet. Our MVP will be a device with a microphone and a camera that can detect your emotion based on your speech and facial expressions. This requires trained neural networks and successful integration of necessary APIs into our model. The device must also successfully communicate with the server, sending data to be computed and receiving the response. Our server should be able to use both the facial emotion and speech data to compute the emotion with 75% accuracy.