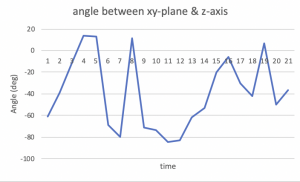
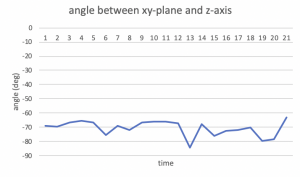
This week, I collected accelerometer data and started working on the fall detection algorithm. Before we get our pi set up, I will use my iPhone to collect the data. When collecting the data, I put my phone in the pocket as our final device will also be used that way. I collected the 3-axis accelerations of me falling forward, backward, sideways, and walking, jumping, running, sitting down, and bending down.
For feature selection, I first tried using the vector magnitude of the three accelerations. Using the magnitude instead of using a list of three accelerations simplifies the algorithm, and I expect that it would give similar results because the graphs of xyz accelerations do not differ a lot from each other as shown in the below graphs.
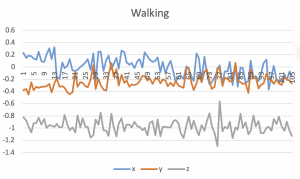


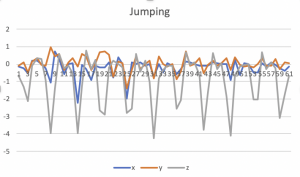
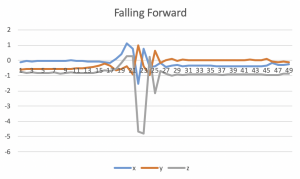
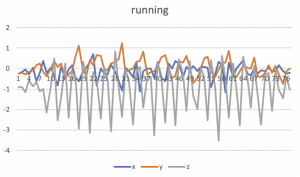
I calculated the magnitude of the acceleration data ((x^2 + y^2 + z^2)^0.5) and split up the data series into a window of size 10. I chose 10 because it covered the peaks in the fall data. However, this could differ from person to person, so I will have to collect more data to make sure that this interval works. I trained the svm using forward fall, side fall, and walking data, and tried testing it. The algorithm detects the all kinds of falls, and classifies sitting and bending as non-falls, but it classifies jumping and running as falls.
For the next week, I will collect more training data from my teammates to compare how the acceleration data differ among people. To improve the accuracy of the algorithm, getting more data for the train set might help. I will also try using the magnitude and angle of the accelerations as a feature. For running and jumping, the magnitude of the acceleration may be similar with the falls but the angle will definitely be different, so it is possible that the algorithm will be able to classify them properly.