
Rene Status Report:
September 23rd 2023
For the first half of this week I was working on our proposal. Given that I was the one presenting, I spent time rehearsing both with my group and individually. We also took time to prepare for any foreseeable questions that may arise during the presentation and also meet with our TA for advice on the same.
For the remainder of the week, I continued exploring parallel programming with HLS on Vitis. I feel more comfortable with coding solutions for simpler tasks such as parallelising basic for loop operations while using a few other pipelining features such as rewinding and flushing. I also took some time to further analyze our algorithms that we had in our proposal (the all pairs and Barnes Hut algorithms). Based on my readings of HLS parallel programming so far, I think it would be easier to start with an all pairs approach and then we could consider the Barne’s Hut as a stretch goal, given the more complex data structures we would need for this (like the recursive QuadTree) and our unfamiliarity with this programming environment. For the remainder of the weekend, Abhinav and I intend to finish our CPU benchmark implementation as we already have a rough implementation from a previous class and would just need to tweak a few things and collect some readings.
30th September 2023
This week I started with refining our CPU implementation to running test cases that matched our use cases (simulating a slightly smaller test set of 10000 particles instead of 50k-100k particles as my original code did), the graphs for break up of the time taken for this simulation is shown below. The reason for this change was that upon further research and testing we found that the Ultra96 v2 FPGA has a maximum of approximately 71k LUTs. We found that running a python implementation using PYNQ on Vitis for 5000 particles had a ~40% LUT usage. We also found some C++ implementations for our FPGA that had a maximum of 12000 particles for their simulations. This would still benefit our targeted user as N-body simulations of this size are very valuable in molecular and astronomical simulations (larger simulations are used for very specific cases like the effects of dark matter on galaxy filaments). I also started looking at places to optimise our code with Abhinav. I think we can take advantage of Vitis’ pipelining pragma to increase the efficiency of our compute force and particle identification section. I have mentioned the same in our design presentation. With respect to our schedule I think we are just about on time. We plan to spend a considerable portion of next week on our design presentation and I then hope to finish my research/ investigations on our algorithm design and start coding up an HLS implementation of our simulation by Fall Break.

This week’s status report question asks about what courses that played a role in designing our project. For me, 15418 (Parallel Computer Architecture and Programming) played a big a role in my ability to understand how to write a parallelisable algorithm and what techniques would best fit my use case. Given that we are working on an FPGA 18240 was very helpful with understanding how different hardware components work and what constraints I must be aware of when solving our problem. I am not very familiar with the Ultra96 FPGA that we are using so I have been leaning on Yuhe (who is taking 18643) and the Xilinx and Vitis documentation for understanding how to write HLS.
7th october 2023
For the first half of this week, I, along with everyone else in our group, spent time polishing our design presentation (Thank you to our TA Cynthia for helping us with this!). We also spent time helping Abhinav rehearse for the same since he was the one presenting this time. Once this was done, I started working on getting Vitis set up on my own computer and then starting our naive N-body simulation (one with no parallel/memory optimisations) to see how Vitis attempts to parallelise our code with Abhinav. This would be important to see what our hardware usage is with our simulation (especially our LUT utilization) as this was an important concern brought up during design presentations. I think we are now slightly ahead of schedule (as I finished benchmarking last week) which should hopefully leave us enough time to prepare our design report due this coming Friday. I also hope to have some code implemented by next week and would like to start testing this during/after fall break.
This week’s status report question asks about what courses that played a role in designing our project. For me, 15418 (Parallel Computer Architecture and Programming) played a big role in my ability to understand how to write a parallelizable algorithm and what techniques would best fit my use case. Given that we are working on an FPGA 18240 was very helpful with understanding how different hardware components work and what constraints I must be aware of when solving our problem. I am not very familiar with the Ultra96 FPGA that we are using so I have been leaning on Yuhe (who is taking 18643) and the Xilinx and Vitis documentation for understanding how to write HLS.
21st october 2023
Before fall break, I worked with Yuhe to generate a hardware utilization report of a naive N-body simulation. This was important as we had some concerns about running out of LUTs for our target simulation size. Using Vitis and Vitis HLS we were able to synthesize and emulate a 15 particle simulation. Synthesizing this on Vitis HLS produced a LUT count of just above 3000. Running a hardware emulation on Vitis produced the following results:

This has a LUT count of 3024, given that this count would also include the computation cost in the simulation, we think that this should scale well with our use case. I, with the rest of our group, also spent a significant portion of time working on our design report as it took some time to write about 10 pages in a research paper style.
With respect to this week’s question, the new tools I will have to learn is mainly understanding how Vitis HLS works. I have already done research on its parallel models and pragmas that we intended to use earlier. I still need to work with Yuhe to understand how it processes an input file to run an n body simulation. I also need to improve my understanding of how the FPGA memory structure works especially if I wish to leverage the advantages of BRAM etc. for our simulations.
With respect to our schedule, we are supposed to finish our integration by the end of next week, which is on track with our current progress and also sets us up well for the interim demo. I hope to start trying some optimisations soon (either next week or the week after).
28st october 2023
This week I helped with finishing setting up our project environment. I refactored sections of our code to make our algorithm a bit more modular for future scopes of parallelism and made some of our code more Parameterisable to make it easier to modify in terms of input length etc. We are now able to synthesize and generate reports of versions of our code. I also wrote a new implementation of our code that takes fixed point numbers using Vitis HLS’s “ap_fixed.h” library as this was an important optimisation that we wanted to try. This was surprisingly challenging given that Vitis has some unusual rules about arithmetic with these custom data types. I also learned that Vitis allows you to choose the size of your custom fixed point number and the portion of it that you want to be fractional. My first implementation was a success from its reports we can see that it decreases our hardware usage significantly (specifically LUTs). I have attached some screenshots of this below. (Note: that I deliberately disable pipelining for our loops).
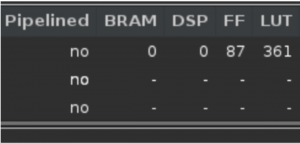
Fixed Points

Floating points
I also spent some time working on the ethics assignment that is due today. With respect to our schedule I think we are making good progress, although some things have taken slightly longer than expected we have not been stuck on anything for too long. I hope to try out more optimisations next week and have some results to show for our interim demo that is coming up.
4th NOVEMBER 2023
This week I helped with synthesizing our code to our FPGA. In addition to this being a big part of our project (as we cannot accelerate our simulations successfully without actually running it on an FPGA), we also had to produce a deliverable for our interim demo that is coming up next week. To start with we had a naive n body simulation running on the FPGA with no optimisations to just test our pipeline. We could not experiment with too many optimisations on the board itself because synthesizing the hardware to the board takes several hours (8+). During this time, I played with using fixed point numbers a bit more. I wanted to see how changing the size of our custom fixed data type affects hardware utilization and its effects on our simulation’s accuracy. Given our design requirement of roughly 90-95% accuracy I think that a 16 bit number would suffice.
In addition to this I also explored some other parallelisation techniques Vitis has to offer. I started with trying one of our main optimizations, Pipelining. This proved not to be as straightforward as I thought. I could not simply apply the pipeline pragma into our code as that exceeded our hardware utilization. This led me to finding memory dependency in our code between our compute force and update particle stages. I also tried experimenting with HLS tasks and this increased our hardware utilization and therefore seemed like a promising optimisation.
So far I think we are on schedule. We have finished setting up our User -> FPGA -> User pipeline and we have begun the final step of our project, applying and experimenting with our optimisations and refactoring our code to achieve the best possible performance. Once we finish our interim demo, my plan is to finish implementing a usable version of our code that has pipelining enabled.
11 November 2023
This week’s focus was dedicated to exploring and implementing various parallelization techniques within Vitis HLS to further enhance our project’s performance. Significant progress was made in experimenting with pipelining and block memory approaches, which are critical for achieving our goal of a 10x speed improvement. This took a bit longer because of some dependencies in our code and ensuring that I don’t exceed our hardware limitations but I am on track in terms of schedule for the week and the plan for next week is to finalize on parallelization parameters like the initiation interval for the pipeline and also plan to finish trying HLS tasks. I will have to conduct further synthesis tests to confirm and see which parameters are best suited for us in terms of speedup. Monday and Wednesday were also spent in class presenting our demo to the TAs and professors.
In response to ABET #6 We have mainly 2 goals from our project. One is a speedup and the other is a test accuracy. Abhinav is currently working on a script which verifies the accuracy of our result but we verified them informally and they seemed to look correct. Should any errors significantly compound over larger number of iterations, I will increase the size of our fixed point type, which may hurt performance but maintain the integrity of our calculations (as its importance was stressed in ethics assignment earlier). As for our speedup we have timing code in our simulation which tells us how much time it took to run which we then compare with our reference solution to verify if it is correct.
18th November 2023
This week I was able to finalize our unrolling, pipelining and task optimisations. With respect to tasks, I found that this is an optimisation that is on a higher level, as in it would create additional control flows almost to a similar degree of a thread or an ISPC task. While this is an interesting form of parallelism, I found it to not be applicable to our use case given that our computation kernel is repeating the same calculations for all iterations (it does not diverge into different control flows) leading to potential overhead synchronization costs. For unrolling, I found that our implementation in the interim demo gave more control to the Vitis compiler to decide our unrolling factor. Vitis tried to unroll our loops with an abnormally large factor which would get rejected by the synthesizer in most cases, leading to us not fully exploiting our available hardware. I spent this week fine tuning this factor and found that a factor of 50 in both compute force and update particle sections of our code produce good util reports as shown below.

We’re using roughly 85% of our available LUTs. This is intentional as we do not want to make our resource utilization too close to our actual bounds to avoid any unexpected behavior. For pipelining, I found the Vitis Interval Violation detector very helpful with choosing an appropriate interval to pipeline, I have shown screenshots of the same below:

Choosing an interval that is too small leads to dependent sections of code overlapping
My final version kept dependent sections of our code independent (blue bars) while still pipelining computation where possible (greenlines)

Given that these optimisations increase the amount of concurrent read/writes into our IO, it was necessary to have our BRAM/local buffers refactored for this. So, Yuhe and I spent the remainder of this week setting this up and we will spend the remainder of the weekend and the week before break testing this. We hope to have our successful final build running by the end of the break so that we can fine tune our fixed point sizes etc. for our accuracy design requirements in preparation for our demo. Overall, I think we are still on schedule, although using BRAM has been somewhat challenging. However, given the reports shown above, I am very excited to see the gain in performance of our version in comparison to our CPU and interim demo times.
2nd December 2023
Significant Progress was made this week. I was unable to contribute much to our algorithm before and during Thanksgiving break as I fell ill. At the start of this week, we tested my first version of unrolling and pipelining I mentioned last week. This led to our code slowing down significantly (roughly 13.7s per iteration which is about 3-4x slower than our base CPU implementation). This was especially confusing at first but we then realised that this was because of me trying to read several pieces of data from a single DRAM port which led to some unrolled/pipelined loops waiting for data. One means of improving this was to widen our DRAM ports but this still did not produce significant speedup. We also ended up losing some performance as we discovered our fixed point implementations lose a lot of accuracy when we run our computation for more iterations (given some numbers require much more precision like the gravitational constant G). This was quite disheartening as we were back to square one with not much time left. Yuhe worked on some versions of batching while I ended up trying to move our entire dataset onto BRAM (we did some preliminary calculations and found that we have roughly 432 KB of BRAM on our board and two copies of our data set, including the temp array would take about 400KB, which is cutting it close but had potential). This build succeeded and brought us back to about 2x speedup with no optimisations! Yuhe then suggested a major code refactor to reorder our loops to remove a data dependency while also removing the need for a temp array. This led to a 7x speedup! I then helped Yuhe with implementing a batching + unrolling iteration of this which gave us a 20-25x speedup surpassing our initial requirements!
I then spent the entirety of today working with getting a graphical display working on the FPGA. This proved to be rather challenging. I succeeded in connecting the board to my laptop with a wired connection. This would be useful in our final demo to avoid any connection issues since the board’s wifi is unreliable. We also managed to view the Board’s OS on a monitor using Abhinav’s new active miniDP cable. This allowed us to connect the board to the internet and install some graphing libraries. We were still not able to plot our results on the board itself but have made some significant progress in the last few days. We are slightly behind schedule, but I will focus with Abhinav to get our display working (or an equivalent solution) working for our final demo next week!
9th December
The day after last week’s status report, we managed to increase our speedup even more! We pushed our batch size to 8 and was able to get a ~40x speedup! (Most credit goes to Yuhe for trying this though). After that, I focused on data collection and finishing up our final presentation. I was able to generate graphs and metrics for our Kernel Runtime breakdown to compare with our CPU implementation, how our different approaches varied with speedup and also some visual images to show this. Abhinav and I also helped Yuhe practice as it was her turn to present.
For the latter half of the week, I helped Abhinav with finalising our graphic display. I looked into the hardware kernel’s IO to see if it were possible to have a separate kernel read the results written into DRAM live so we could stream our data in real time. This unfortunately did not seem like a viable approach. This would involve some complex synchronization infrastructure between the two kernels and while I am familiar with this is in traditional concurrent programming (like C, Go, CUDA etc.), I have not implemented this in hardware before. Further digging into this lead me to realising that our kernel spends longer loop iterations on actually read/writing to DRAM and then to its output file than our actual computation (since this is parallelised), so even if I were to implement the above mentioned scheduling, it would hurt our performance significantly. What I chose to do as a result was to modify our kernel and write a bash script that calls the kernel for a sample number of iterations on repeat and then issues an HTTP POST request to the server that Abhinav set up. This was a success! The server displays our animations and also has the option to download files on the go instead of needing to be near the board to receive its results. For viewing the results of a simulation live, we have roughly 3-4 fps.
With our schedule I think we are finally done with the implementation and integration side of our project and now will focus on preparing to present our work for the final demo and finishing up our report. Overall I think we are in a good place and am happy with what we have achieved this semester!