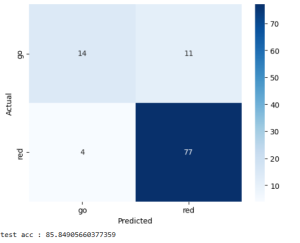
Using our models, I manually implemented visualizations of the bounding boxes identified by the model in the images sampled, and printed out any feedback prompts that would be relayed to the user on the top left of each image.



Visually inspecting these images, we see that not only do the bounding boxes look accurate to their identified obstacles, but that we are able to use their positional information in the image to relay feedback. For sample, in the second image, there is a person coming up behind the user on the right side, so the user is instructed to move to the left. Additionally, the inference speed was very quick; the average inference time per image was roughly 8ms for the non-quantized models, which is an acceptably quick turnaround for a base model. I haven’t tried running inference on the quantized models, but previous experimentation has indicated that it would likely be faster. As such, since the current models are already acceptably quick, I plan on testing the base models on the Jetson Nano first before I attempt to use to quantized models to maximize performance accuracy.
Currently, I am about on schedule with regards to ML model integration and evaluation. For this week, I plan on working with the staff and the rest of our group to refine the feedback logic given by the object detection model, as currently the logic is pretty rudimentary, often giving multiple prompts to adjust the user’s path when only one or even none are actually necessary. I also plan on integrating the text to speech functionality of our navigation submodule with our hardware if time allows. Additionally, I will need to port the object detection models onto the Jetson Nano and more rigorously evaluate the speed on our hardware, so that we can determine if more intense model compression will be necessary to make sure inference and feedback are as quick as we need it to be.