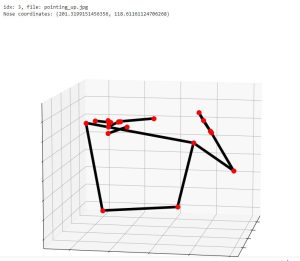
Coming into the final week, our project design consists of running MediaPipe’s HPE and classification model directly on the Jetson and connecting to OpenAI’s API for the LLM portion. A web server will be hosted locally through Node.js and display the video feed alongside any detected text. This week, we’ve focused on retraining our word classification algorithm and finalizing the integration of project components.
The main risk in the coming week before project demos would be unexpected failure of a subsystem before demo day. To combat this, we will document our system as soon as desired behavior is achieved so there is proof of success for final proof of concept. If retraining the word classification model lowers accuracy or creates failure due to the complexity of 2000 classification labels, we will demo using the smaller word classification models that have been trained earlier in the semester.
We are on track with our last schedule update and will spend the majority of the next week finishing project details.
When measuring project performance for final documentation, we used the following unit tests and overall system tests:
- Overall and Unit Latencies were calculated by running a timer around specific project components.
- The speed of our overall latency encouraged us to focus on accuracy and range of word classification rather than reducing latency. As such, we’re retraining our word classification model to identify 2000 words as opposed to our current 100.
- Recognition Rate was tested through measuring output/no output of the classification model in tandem with short video clips.
- Word Classification Accuracy was measured by running video clips of signs through the classification model and checking the output value against the video’s correct label.
- Inference Accuracy has been primarily gauged through human feedback when testing various LLM models’ need for reinforcement or fine tuning. A more complete dataset, predominantly informed by SigningSavvy, will soon be used to collect model-specific accuracy metrics.
 here, you can see a few syntactically ASL sentences correctly translated to natural language English sentences.
here, you can see a few syntactically ASL sentences correctly translated to natural language English sentences.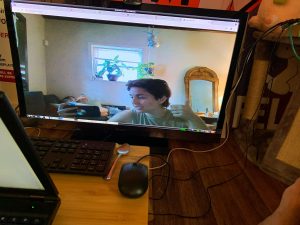 I was able to successfully install Node on the Jetson and create a simple local web server that displayed webcam input on a browser using the livecam library. As seen to the left, the monitor displays a live stream of the webcam connected to the Jetson. I have limited experience with front end development but will shortly be adding text and interactive features to the display.
I was able to successfully install Node on the Jetson and create a simple local web server that displayed webcam input on a browser using the livecam library. As seen to the left, the monitor displays a live stream of the webcam connected to the Jetson. I have limited experience with front end development but will shortly be adding text and interactive features to the display.