This week was decently busy as my group members and I prepared for the interim demo. While not all of the components are properly connected together at this moment, we made good process on each of the subcomponents. I made some additional progress based on feedback and takeaways from the ethics discussion class since the last time we presented during our team meeting.
During this stage where we were trying to merge components of the web application including Surya’s scale readings, Steven’s ML classification, and my frontend additions for the user, there were conflicting changes that prevented pulls from our respective branches. Additionally, there were authentication issues that came up with certain additions, so I had to trace back to the most recent git commit that did not have this problem. This caused a lot of lost time to work on the functionalities, so the additional time to figure out the authentication problems we were kindly granted allowed me to finish most components we planned on having on our website.
To elaborate on the additions, I will include screenshots and explanations of pages included in our demo below:
Our WebSocket library and server have already been set up, but latency issues still persist so during the validation phase, I will look more into content delivery networks or choosing a different message format to minimize additional network traffic. For now, the page is able to display chat messages that are updated in the UI but more testing during the deployment stage will have to be done to ensure users are receiving their respective messages.
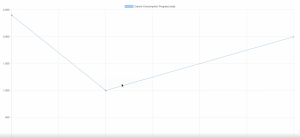
The calorie consumption progress page below is something we considered when brainstorming how to improve the user experience and provide more fitness encouragement. By displaying such a line graph of all of the user’s daily tracking, they are able to see their overall improvement after using our application. I ran into issues with rendering the inputted data and customizing the graph to update with each additional update. Enough testing was implemented to ensure efficient data synchronization between the client as well as the server.
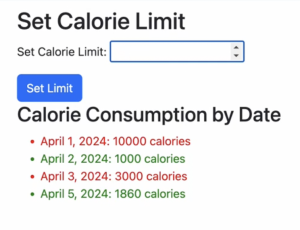
This page is more to show proof of concept since there is still more work to be done with connecting the classification and scale readings to the cloud database. But essentially, inputting values for a certain day will be retrieved and displayed in the rendered chart below. I was having trouble saving values from previous days, but that is something that would be included in the end product to show progress. Perhaps a diagram that can directly compare improvements and vice versa.

Lastly, also for proof of concept and connected to the data retrieved from the previous calorie progress tracking page, users can set a calorie limit to see whether or not they have exceeded this limit on a daily basis. This is achieved through a simple if-else statement on the HTML page where red means they have exceeded their set calorie limit, and vice versa for green entries.
To answer this week’s additional prompt, more testing has to be done regarding individual components I am working on as well as API integrations. For instance, unit testing will be done to ensure the backend is able to reject invalid data like negative calorie entries or if a certain limit is exceeded. CRUD operations will need to be tested to ensure they work correctly and this changed data would be stored correctly. This would include deleting chats between users, deleting posts or comments under posts, or deleting caloric entries under the different pages that include these functionalities. In addition to proof of concept, we will also include deleting entries that will be added to total daily consumption.
Some basic testing for user security would be compatibility between different browsers to ensure consistent behavior across them, usability testing to gather navigation feedback and general user interface feedback, and more security tests. Previously, I conducted tests on SQL injection and cross-site scripting attacks. Since OAuth is an inclusion, proper authentication as in only CMU users are able to use this application upon signing in. Another thing that will be considered is file upload testing. Users are uploading profile pictures or (for now) pictures for posts that will eventually be pictures from the camera scanning, vulnerabilities will have to be tested to ensure malicious files would not compromise the server.
Considering most of our subsystems have not been connected together yet, I plan to finish all my testing to prevent future complications with my specific subsystem. Specific requirements that must be met include proper updating and including as many vulnerability prevention measures as possible for most common security vulnerabilities. I look forward to further discussion with my group members and identifying important validation points for the merging of subcomponents.