Main Accomplishments for The Past Two Weeks
* Major work was accomplished in the week of 3/2 as the spring break was planned as slack week.

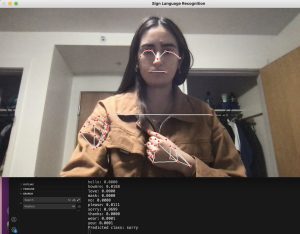
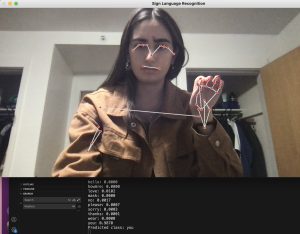
- ML model training for dynamic signs

- Mobile app’s Video recording & saving capabilities

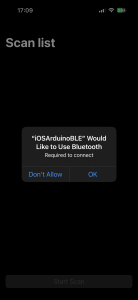
- Cloud environment setup in AWS Amplify
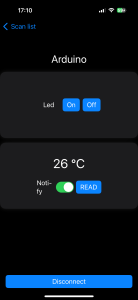
- Hardware components setup and connection
Risks & Risk Management
While the expected basic functions are being implemented and carried out, we have encountered issues in low quantitative performances, including prediction accuracy and overall latency.
- The static ML model is tested to predict relatively accurate single letters from the real-time signing, but the two dynamic ML models we have incorporated and trained so far produced errors in live signing testing. We are re-examining the way we extracted landmarks from the CV module to debug. In case of severe difficulties in dynamic sign prediction, we would pivot to a fallback mechanism that recognizes only static signs, leveraging existing models specifically trained for static sign recognition.
- Another issue lies in the way we store and transmit data. At the present stage, the mobile app captures and stores the camera input in the photo album as .mov file, which is likely to be stored as the same format in S3 database after we fully set up the AWS Amplify cloud environment. However, we aim for real-time, streaming-like transmissions, which means the current solution – saving the file after pressing stop recording – does not satisfy our requirements. We will conduct further research on reliable live transmission methods to solve this issue. The backup plan of a laptop-based web app that uses the webcam would be used if no feasible mitigations are available.
Design Changes
Schedule Changes
Additional Week-Specific Questions
Part A was written by Leia, Part B was written by Sejal, and Part C was written by Ran.
Part A: Global Factors (Leia)
Our project addresses a variety of global factors with its practicality. For those not technologically savvy, our procedure to install and utilize our translator is not complex nor difficult. Simply by downloading the app and attaching the display module to the phone, the translator is immediately functional. It is not restricted to one environment either, but intended to be used everywhere for many situations, from single-person conversation to group interactions. Additionally, its purpose is for the hard-of-hearing community, but can technically be accessed by anyone, including the speaking community. Admittedly, because we are focused on American sign language rather than the international variation and do not include other nations’ versions, our product is not global in this aspect. However, its ease of use makes it versatile for anyone who uses American sign language in communicating with anyone who speaks English.
Part B: Cultural Factors (Sejal)
Cultural factors such as language and communication norms vary among different groups of people. Our solution recognizes the importance of cultural diversity and aims to bridge communication barriers by facilitating real time ASL translation. For the deaf community specifically, ASL is not just a language but also a vital part of their cultural identity. The product acknowledges the cultural significance of ASL by providing accurate translations and preserving the integrity of ASL gestures, fostering a sense of cultural pride and belonging among ASL users. By displaying written English subtitles for non-ASL users, the product promotes cultural understanding and facilitates meaningful interactions between individuals with different communication preferences, aiming to build inclusive communities. Additionally, the portable design of the product ensures that users can carry it with them wherever they go, accommodating the diverse needs and preferences of users from different cultural backgrounds.
Part C: Environmental Factors (Ran)
Our product does not pose harm to the environment and consumes a minimal amount of energy resources. Our hardware is composed of an OLED screen, a Li-Ion battery, an arduino board, and a 3-D printed phone attachment. The OLED screen lasts longer than traditional display technologies with the same amount of energy, and it uses organic compounds that are less harmful in manufacturing processes. The rechargeable Li-Ion battery also reduces overall electronic waste by almost eliminating the need for replacement. So, the battery and screen supports our product’s sustainability by their extended use period and long lifespan. In addition, we enhance the environmental advantages with the choice of a 3D printed phone attachment from polylactic acid (PLA) filaments. This material is derived from renewable resources, such as cornstarch or sugarcane, contributing to a reduction in reliance on finite fossil fuels. Moreover, the lower extrusion temperatures required for PLA during printing result in decreased energy consumption, making it a more energy-efficient option. Most importantly, PLA is biodegradable and emits fewer greenhouse gasses, including volatile organic compounds (VOCs).
Meanwhile, our product is small in size and is highly portable, whose operation does not require external energy input other than the phone battery and the Li-Ion battery, nor does it produce by-products during usage.