Main Accomplishments for This Week
- Transporting our current ML implementation into CoreML to be iOS app compatible
- Adapting our app CV input to work with the ML program
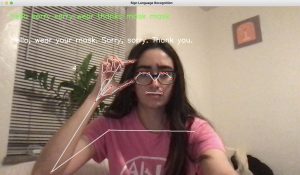
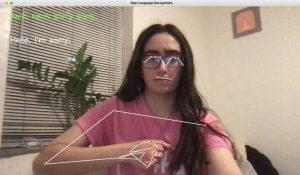
- Successful integration of the LLM model to grammatically fix direct ASL translations into proper sentences
- Hardware approaching near completion with app to screen text functionality
Risks & Risk Management
- As we’re in the final week of our project, possible risks are issues with the total integration. The CV and ML are being worked on in one app and the Arduino and bluetooth screen in another, so eventually they will have to be merged together.
- The risk mitigation for this is careful and honest communication across all team members. We don’t anticipate this to fail severely, but in the off chance that we cannot get them to combine, we will discuss which app to prioritize.
- Another related concern that carries from last week is the difficulty incorporating a pose detection model as MediaPipe lacks it for iOS. This may lead to reduced accuracy, and our fallback if it continues to be unavailable is to focus entirely on hand landmarks.
Design Changes
- No design changes
Schedule Changes
- We added an extra week for NLP training and for the final system integration.

Additional Week-Specific Question
- Our validation tests for the overall project involve:
- Distance tests to measure how close or far user needs to be from app camera
- Our use case requirement was that the person must be between 1-3.9ft from the iPhone front camera, so we will test distance inside and out of this range to determine if it meets this requirement.
- Accuracy of ASL translations displayed on the OLED screen
- Our use case requirement was that the accuracy for gesture detection and recognition should be >= 95%, so we have to ensure the accuracy meets this requirement
- Latency of text appearing on screen after gestures signed
- We also have to ensure our latency meets the requirement of <= 1-3 seconds, consisting of the ML processing, LLM processing, and displaying on the OLED screen.
- Accessibility and user experience surveys
- We will get ASL users to test out the device and collect feedback through surveys in order to reach out user satisfaction rate requirement of > 90%
- Distance tests to measure how close or far user needs to be from app camera