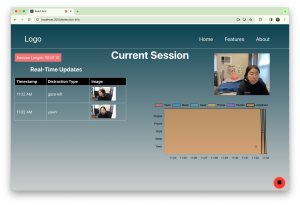
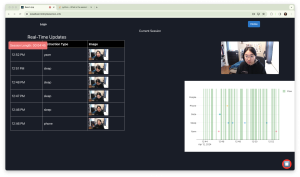
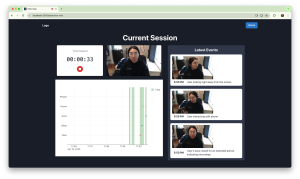
This week I wrapped up the phone pick-up detection implementation. I completed another round of training of the YOLOv8 phone object detector, using over 1000 annotated images that I collected myself. This round of data contained more colors of phones and orientations of phones, making the detector more robust. I also integrated MediaPipe’s hand landmarker into the phone pick-up detector. By comparing the location of the phone detected and the hand over a series of frames, we can ensure that the phone detected is actually in the user’s hand. This further increases the robustness of the phone detection.
After this, I began working on facial recognition more. This is to ensure that the program is actually analyzing the user’s facial features and not someone else’s face in the frame. It will also ensure that it is actually the user working and that they did not replace themselves with another person to complete the work session for them.
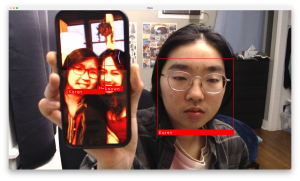
I had first found a simple Python face recognition library, which I did some initial testing of. Although it has a very simple and usable interface, I realized the performance was not sufficient as it had too many false positives. Here you can see it identifies two people as “Karen” when only one of them is actually Karen.
I then looked into another Python face recognition library called DeepFace. This has a more complex interface, but provides much more customizability as it contains various different models that can be used for face detection and recognition. I did some extensive experimentation and research of the different model options for performance and speed, and have landed on using Fast-MTCNN for facial detection and SFace for facial recognition.
Here you can see the results of my tests for speed for each model:
❯ python3 evaluate_models.py
24-03-21 13:19:19 - Time taken for predictions with VGG-Face: 0.7759 seconds
24-03-21 13:19:20 - Time taken for predictions with Facenet: 0.5508 seconds
24-03-21 13:19:22 - Time taken for predictions with Facenet512: 0.5161 seconds
24-03-21 13:19:22 - Time taken for predictions with OpenFace: 0.3438 seconds
24-03-21 13:19:24 - Time taken for predictions with ArcFace: 0.5124 seconds
24-03-21 13:19:24 - Time taken for predictions with Dlib: 0.2902 seconds
24-03-21 13:19:24 - Time taken for predictions with SFace: 0.2892 seconds
24-03-21 13:19:26 - Time taken for predictions with GhostFaceNet: 0.4941 seconds
Here are some screenshots of tests I ran for performance and speed on different face detectors.
OpenCV face detector (poor performance):

Fast-MTCNN face detector (better performance):

Here is an outline of the overall implementation I would like to follow:
- Use MediaPipe’s facial landmarking to rough crop out the face
- During calibration
- Do a rough crop out of face using MediaPipe
- Extract face using face detector
- Get template embedding
- During work session
- Do a rough crop out of face 0 using MediaPipe
- Extract face using face detector
- Get embedding and compare with template embedding
- If below threshold, face 0 is a match
- If face 0 is a match, everything is good so continue
- If face 0 isn’t a match, do same process with face 1 to see if there is match
- If face 0 and face 1 aren’t matches, fallback to using face 0
- During work session
- If there haven’t been any face matches in x minute, then user is no longer there
Although I hoped to have a full implementation of facial recognition completed, I spent more time this week just exploring and testing the different facial recognition options available to find the best option for our application, and outlining an implementation that would work with this option. Overall, my progress is still on schedule taking into account the slack time added.