This week we mainly worked on the final presentation and slides and made sure that we had all the information presented well. We also worked on making final adjustments to the overall integration of all three components and we will continue to work on this for the rest of this week as well before the final demo on Friday. The most significant risk at this time is making sure that we are able to successfully demo our final product and we can ensure that everything goes well by doing several practice runs this week. We are all very confident that our demo will go well and are looking forward to completing our final product. We are all on schedule as well and were able to stay on track with the Gantt chart that we made earlier this semester. For next week, we will make sure to submit the final poster, video, and report.
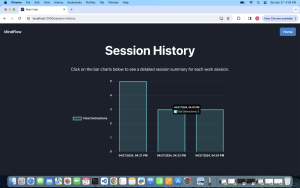
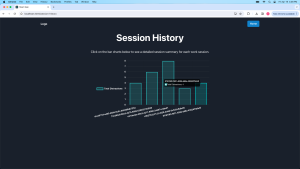
Below are the unit tests and overall system tests carried out for experimentation of our system for the Camera-Based Detection. For the EEG, the test results/ procedure were outlined in Rohan’s individual report last week.
- Yawning, microsleep, gaze, phone, other people, user away
- Methodology
- Test among 5 different users
- Engage in each behavior 10 times over 5 minutes, leaving opportunities for the models to make true positive, false positive, and false negative predictions
- Record number of true positives, false positives, and false negatives
- Behaviors
- Yawning: user yawns
- Sleep: user closes eyes for at least 5 seconds
- Gaze: user looks to left of screen for at least 3 seconds
- Phone: user picks up and uses phone for 10 seconds
- Other people: another person enters frame for 10 seconds
- User is away: user leaves for 30 seconds, replaced by another user
- Results
- Methodology

- Overall system usability and usefulness
- Methodology
- Test among 10 different users
- Have them complete 10 minute work session using the app
- Ask after if they think the app is easy to use and is useful for improving their focus
- Results
- 9 of 10 users agreed
- Methodology
- Data capture and analysis latency
- Methodology
- Video processing
- Measure time between processing of each frame
- Get average over a 5 minute recording
- Video processing
- Results
- Video processing
- 100 ms
- Focus/flow detection
- 0.004ms
- Video processing
- Methodology