
This week, I focused on flow state validation, developing/validating a focus detector, and applying Shapley values to provide explainability to our black box flow state neural network.
For the flow state detection validation, I wore noise canceling headphones while playing Fireboy and Watergirl which is a simple online video game for 15 minutes. Then, for the next 15 minutes, I worked on implementing the model validation script without noise canceling headphones with ambient noises in the ECE work space and frequent distractions from Karen. At the end, we looked at the percentage of time the model classified as in flow for each recording and saw that .254% of the intended flow state recording was marked as flow and .544% of the intended not in flow state recording was marked as flow. These results obviously are not what we expected, but we have a few initial thoughts as to why this may be the case. First of all, Fireboy and Watergirl is a two person game and I was attempting to play by myself which was much more difficult than I expected and definitely not second nature to me (necessary condition to enter flow state). As such, we plan to test our flow state model on my roommate Ethan who plays video games frequently and apparently enters a flow state often while playing. By validating the model on an activity that is more likely to actually induce a flow state, we expect to see better results. If this ends up not working, we plan to return to the music setting and see how the model performs on the pianists we trained it on and then test on pianists we have not trained on before to further understand where the model may be overfitting.
I also developed a focus detection system which was trained on focused and distracted recordings of Arnav, Karen, and myself. We validated this data by collecting another set of focused and distracted data on Karen, but unfortunately this also had poor results. For the focused recording, our model predicted that 12.6% of the recording was in focus and for the distracted recording, it predicted that 12.3% of the recording was in focus. I realized soon after that the training set only had 34 high quality focus data points of Karen compared to 932 high quality distracted data points. This skew in the data is definitely a strong contributor to our model’s poor validation performance. We plan to incorporate this validation data into the training set and retry validating this coming week. As a backup, we inspected the Emotiv Focus Performance Metric values on this data and saw a clear distinction between the focus and distracted datasets which had average values of .4 and .311 respectively on a range from 0 to 1.
Finally, I applied Shapley values to our flow state model to ensure that our model was picking up on logical features and not some garbage. The SHAP package has a wide variety of functionality, but I specifically explored the KernelExplainer Shapley value approximater and the summary_plot function to visualize the results. Because computing Shapley values over a large dataset, even via approximation methods, can be extremely computationally intensive, I randomly select 500 samples from the dataset to compute the Shapley values on. The basic summary plot shows the contribution each feature makes on each of the 500 points towards a classification of flow. The bar summary plot shows the mean absolute contribution of each feature to the output classification in either direction (i.e. flow or not in flow). We see that the High Beta and Gamma frequency bands from the AF3 sensor (prefrontal cortex) as well as the Theta frequency band from the Pz sensor (parietal lobe) have high impact on the model’s classification of flow vs. not in flow state. These plots allow us to better understand which parts of the brain and more specifically, which EEG frequency bands have the most correlation with flow states in the music setting. Because flow states are difficult to induce and detect with high granularity, having access to high quality flow state ground truth from Professor Dueck is extremely valuable. Given her extensive experience with detecting flow states, and Shapley values’ ability to explain the contributions of each input to the final output, we can make new progress in understanding what kinds of brain activity corresponds with flow states.
Basic Summary Plot:
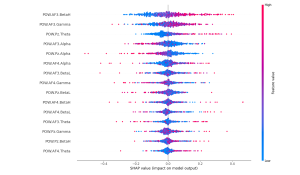
Bar Summary Plot:

