Accomplishments
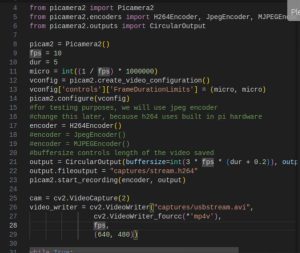
In the past 2 weeks, Brian and I collaborated together for most of the work. To start, Brian and I managed to get uploading from our Raspberry Pi’s to S3 working, and then we were able to download as well. After that, we came up with a really simple synchronization method, which was just uploading a .txt file to indicate an upload was complete and then downloading the .txt file frequently to check if an upload had occurred (since the file is very small, there’s negligible cost to doing this).
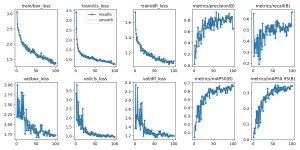
Brian and I then worked on line detection, in which we used YOLOv8’s pretrained model for detecting people, using the bounding boxes to keep track of their location, and then determined whether people should be considered in line by distance and angle between them. To make it more robust, we tried to add functionality to only count people as in the line if they’ve stood still for a few seconds, which should eliminate people just passing by. However, we weren’t able to get this to work reliably. I was thinking of implementing pose detection instead, so we could eliminate counting passersby by checking whether they are facing forward (in line) or facing to the side (passing by), but we will do this next week if we have the chance.
Lastly, we spent some time testing in Salem’s this week. We spent Monday trying to set up and resolve Wi-Fi issues between our RPi’s and Salem’s. We went back on Thursday and managed to get some good footage using an actual checkout lane to test our individual components. We also went earlier today, but were unfortunately not allowed to test this time.
Progress
The main issue is that we didn’t get as much testing done as I would have liked (and also not enough to create much of a presentation). I’m planning to go back to Salem’s tomorrow and try again at a better time for them. Less importantly, I was going to try and implement pose detection to improve our line detection.
New Knowledge
Since I haven’t done anything with computer vision previously, I had to learn how to use OpenCV, which I accomplished by completing a short boot camp from their website. Afterwards, I mostly used YOLOv8’s documentation along with a few articles I found online to learn how to train a model and run inference with it. Afterwards, I used some more online articles to figure out how to set up a headless RPi. For accessing the camera module, I used the picamera2 documentation and some of the examples that I found inside. Lastly, I had to use forums quite frequently when I ran into issues setting up (stuff like how to download packages and change the WiFi settings).