Accomplishments
This week, I went to Salem’s with Simon and Shubhi early on in order to get approval to test our full system, but we weren’t able to do so then because of availability issues with the IT lead. Simon and I then went later on in the week, and we were able to get approval to test, and we got some data to use for testing our fullness calculating module and line counting module. I also went to Giant Eagle this week and took pictures of a few different cart configurations (mostly very full carts), like so:


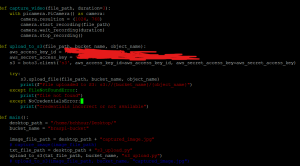
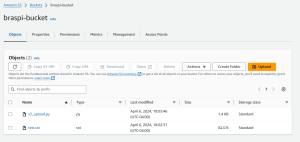
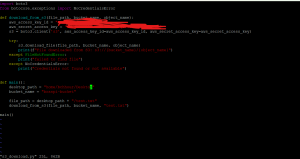
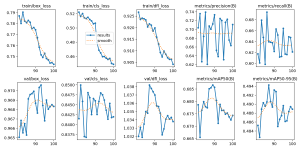
Because there is noise (in the surroundings), I cropped out the images according to the bounding boxes displayed when running the shopping cart model alone and tested relative fullness on them, but found that extremely full carts are for some reason hard to detect with the current implementation. I will need to refine the implementation in the next few days in order to hopefully improve accuracy, but the module seems to work fine with carts that aren’t as full. Testing the relative fullness module on the test footage we got from Salem’s, results are very similar. The carts with much less seem to be much more accurately counted for by the relative fullness module than the carts that are nearly full. I have tried decreasing the amount of Gaussian blur in order to increase accuracy, and while the returned fullness values are somewhat more corrected, they are still quite inaccurate (returning 65% fullness for the above picture on the left), which is concerning. I have also worked on testing the upload and download speed of different length videos, and I’ve created graphs of the relationship between video length and upload/download time. My internet is a bit spotty, so I am not sure if this graph is a completely accurate depiction of the relationship between the video time and the upload/download times. Here is my code and the resulting graphs:

| Duration | Upload Time (Averaged over 10 trials) | Download Time (Averaged over 10 trials) |
| 1 second | 0.61s | 0.32 s |
| 2 seconds | 0.92 s | 0.47 s |
| 3 seconds | 1.35 s | 0.53 s |
| 4 seconds | 1.52 s | 0.55 s |
| 5 seconds | 1.61 s | 0.57 s |
| 6 seconds | 1.65 s | 0.59 s |
| 7 seconds | 1.80 s | 0.68 s |
| 8 seconds | 1.92 s | 0.72 s |
| 9 seconds | 2.21 s | 0.76 s |
| 10 seconds | 2.3 s | 0.88 s |

Progress
In terms of progress, we are still behind schedule by quite a bit. We should be testing the fully integrated system by now, but we have run into a few roadblocks with testing at Salem’s due to discomfort from the cameras by the employees. However, since we figured out workarounds to these issues, we should hopefully be able to get testing done by tomorrow or Monday in the worst case. I will work on trying to increase fullness calculation accuracy for the next day or two while we continue to gather testing data.