Accomplishments
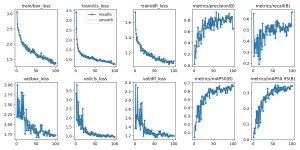
I presented this week. I also went to Salem’s three separate times to try and get footage to test with, but was only successful the 3rd time (see Brian’s status report for more details). I did discuss alternative camera angles for our cashier throughput camera with the manager and the cashiers on my first visit this week (so I didn’t go for nothing), so I realized that I would need to train another model for the new angle (this time, a generalized one using the EgoHands dataset). The model seems to perform rather well, but we need to confirm tomorrow with further testing at Salem’s. On the 3rd visit, I got some data to replace the lost footage from last week, and realized that my shopping cart detection model was also failing to perform on our new camera angle for the small shopping carts (which was surprising, because it worked both from overhead and from a side view, but I guess there was insufficient training data for in between the two angles?). I annotated and added our new images of carts into the old dataset and retrained the model, which is now somewhat improved in terms of performance. However, I’m not confident that it predicts with high enough confidence on carts (it’s around .5 confidence), so we will need to test this as well to see if it ends up being reliable enough. If not, I will probably try to get more footage and just add more data, at the risk of overtraining the model to Salem’s.
Progress
Obviously, we are still very behind. We need to go to Salem’s tomorrow and finalize testing by Monday so that we can prepare for the final demo. As such, I haven’t bothered with the pose estimation for line detection that I mentioned last week, since failure to detect shopping carts/throughput is a much more pressing issue. Also, we need to configure the RPi’s to CMU wifi for the final demo (which is weird with CMU-DEVICE), but we can just use a phone hotspot instead, so this isn’t much of a concern.