What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
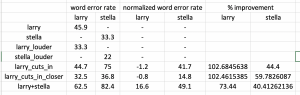
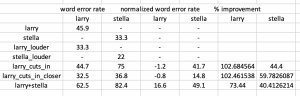
This week, our team discussed with Professor Sullivan and we highlighted the three main priorities that we want to achieve by our final demo.
- Collecting data from different environments. This is because our deep learning system may work better in some environments than others (All)
- Fully integrating our audio and visual interface, as we are currently facing some Python dependency issues (Larry)
- Setting up a UI interface for our full system, such as a website (Me)
I decided to handle the last priority as I have former experience writing a full website. The following shows the progress that I have made so far.
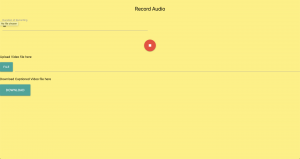
In my experience, I prefer writing websites from a systems perspective. I make sure that every “active” component of the website works before I proceed with improving the design. In the above structure, I have made sure that my website is able to receive inputs (duration of recording + file upload) and produce output (downloadable captioned video).
“ Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
We are on schedule, as we are currently in the integration face of our project.
“ What deliverables do you hope to complete in the next week?
In the coming weekend and week, I will be improving on the visual design of the website.
Larry and I also ran into some problems with the GPU on the jetson. When we run on speech separation on the Jetson, it was taking about 3 minutes, which is rather strange given that the same script took about 0.8s on poorer GPUs on Google Collab. I suspect that the GPU on the Jetson is broken, but Larry disagrees. This week we will try to debug to see if the GPU actually works.