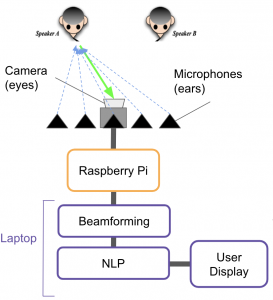
“ What did you personally accomplish this week on the project? Give files or
photos that demonstrate your progress. Prove to the reader that you put sufficient effort into the project over the course of the week (12+ hours).
This week, I implemented image segmentation using Detectron2 to identify the location of only humans in the scene.

The image on the left is the test image provided by the Detectron2 dataset. Just to be certain that the image segmentation method works on non-full bodies and difficult images, I tested it on my own image. It appears that the Detectron2 works very well. Thereafter, I wrote the network in a modular method so that a function that outputs the location of each speaker can be easily called. The coordinates will then be combined with our angle estimation pipeline (which Larry is currently implementing).
“ Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
I would say we are slightly behind, because I was surprised at how difficult it was to separate the speech of two speakers even with the STFT method. I had previously implemented this method in a class and tested that it worked successfully. However, it did not work on our audio recordings. I am currently in the process of debugging why that occurred. In the meantime, Stella is working on delay-and-sum beamforming which is our second attempt at enhancing speech.
“ What deliverables do you hope to complete in the next week?
In the coming week, I hope to be able to get the equations for delay-and-sum beamforming from stella. Once I receive the equations, I will then be able to implement the generalised sidelobe canceller (GSC) to determine if our speech enhancement method works (in a non-real-time case). In the event that GSC does not work, my group has identified a deep learning approach to separate speech. We do not plan to jump straight to that as it cannot be applied in realtime.