What are the most significant risks that could jeopardize the success of the project? How are these risks being managed? What contingency plans are ready?
The most significant risk that can jeopardise our project is linking the front-end (website) to the backend (processing). Larry and I will be working on this integration before our final demo day. The contingency plan is that we demo the front end and the back end separately. We already have a pipeline set up to record, split and overlay captions on the video, which is our MVP.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
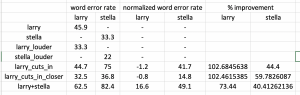
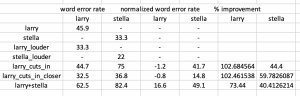
Yes. We are probably going to use a deep learning approach in separating speech given that the results we are getting is spectacular. This change was necessary as a conventional signal processing method given our microphone array is not sufficient in separating non-linear combination of speeches. Deep learning approaches are known to be able to learn and adapt to non-linear manifolds of the training instance. This is the reason why our current deep learning approach is extremely successful in separating overlapping speech.
At the moment, we decided to not do real time due to the deep learning approach limitations. Therefore, we replaced this with a website interface that allows users to upload their own recordings for text overlay.
Provide an updated schedule if changes have occurred.
No change to schedule.
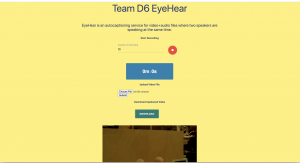
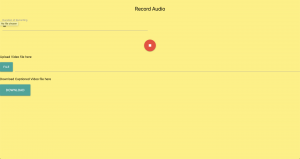
This is also the place to put some photos of your progress or to brag about a component you got working.
We did our final data collection on Friday with the new microphones.
The microphones are unidirectional, placed 10cm apart. Speakers are seated 30 degrees away from the principal axis for two reasons. First, it is the maximum field of view of the jetson camera. Second, it is the basis of our pure signal processing (SSF+PDCW) algorithm.

We split the audio and overlay the text on the video. This is a casual conversation between larry and charlie. As we expected, the captioning for charlie is bad given his Singaporean accent, but larry’s captioning is much better.
https://drive.google.com/file/d/1zGE7MbR_yAVq2upUYq0c2LfmLz1AmquT/view?usp=sharing