
What are the most significant risks that could jeopardize the success of the project? How are these risks being managed? What contingency plans are ready?
The current most significant risk is to integrate the camera and audio modules together. We are facing quite a bit of python compatibility issues on the Jetson. We have a naive solution (contingency), where we write a shell scripts that execute each of the module using a different version of python. However, this is extremely inefficient. Alternatively, we are thinking of resetting the Jetson or at least resetting the jetson module.
We are also having troubles using a complete digital signal processing approach in separating speech. We realised that beamforming was not sufficient in separating speech, and have turned to Phase Difference Channel Weighting (PDCW) and Suppression of Slowly-varying components and the Falling edge of the power envelope (SSF), which Stella is currently testing.
The contingency plan is a deep learning speech separation approach. Charlie has obtained significant success in using deep learning to separate speech, but the deep learning model he has used cannot be used in real-time due to processing latency. We demonstrated it during our demo during the week, and showed the results of using this deep learning approach. Professor Sullivan and Janet seem sufficiently convinced that our approach is logical.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)? Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
Yes. We are probably going to use a deep learning approach in separating speech given that the results we are getting is spectacular. This change was necessary as a conventional signal processing method given our microphone array is not sufficient in separating non-linear combination of speeches. Deep learning approaches are known to be able to learn and adapt to non-linear manifolds of the training instance. This is the reason why our current deep learning approach is extremely successful in separating overlapping speech.
Provide an updated schedule if changes have occurred.
No change to schedule.
This is also the place to put some photos of your progress or to brag about a component you got working.
The biggest thing to brag about this week is numerical values to show how successful our deep learning approach is
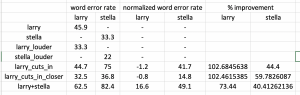
When one speaker is speaking (isolated case), we get a Word Error Rate (WER) of about 40%. We tested two cases where two speakers are speaking at once, and when one speaker interrupts. Using our speech separation technique, we are getting a nearly comparable WER as compared to the isolated case.