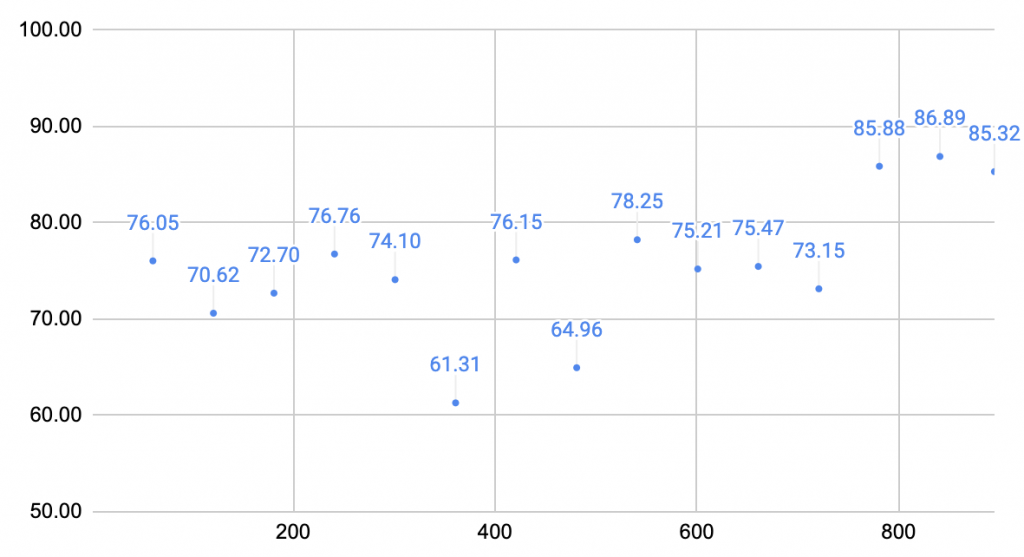
For the week, I had to present our final presentation. I worked on my portion of the slides, which included work left to be done and verification and testing. I asked my teammates to leave me some things to say so I could present their slides, but Lulu failed to include anything. Luckily, half of her slides were very similar to slides I had made for previous presentations so I was able to come up with things to say on the spot because she had not informed me that she left me with nothing. After seeing all of the interesting presentations that the other teams had put together, I focused in on continuing my testing of the system. I ran longer tests to get a better grasp of the true accuracy (however close I can understand of it) of the decision making process. I expanded my testing to include spreads of more than 2 FPGAs, including 6 boards and 10 boards, changing the scaling up process to 2-6-10 instead of 2-5-10. This made more sense as we can start from an equilibrium state regardless of the number of FPGAs. I also ran tests on the thresholds with which we decide to change configurations to better improve the overall robustness of the system. I came up with different ways to make the algorithm more robust to sudden volatility spikes that may change the configuration and make the FPGAs reset unnecessarily. I also made plans with the team to work on the poster, but Lulu remains inactive, so might have to work on that only with William. I also await Lulu’s response to my asking of her status update on the receiving code.
In terms of my schedule, I am on time. I conducted tests and will analyze my data with better numbers from lessons I learned during my own presentation. Since Lulu is unresponsive, I can only try to keep helping William with the Ethereum miner implementation.
We also have to begin writing the final report in addition to finishing the poster.
Attaching a small sample of the many graphs I’ve generated and analyzed