
This week I tried working on the tasks using the RPi, mainly debugging the GPIO communication functions I wrote last week. We still need to work out a way to work on the RPi with CMU secure wifi, so we are doing RPi related tasks at home this week. Although David managed to ssh into the RPi at home using the ethernet connection, I couldn’t ssh into the RPi with the same ethernet connection, even though we literally live in the same building. I’ve looked into others ways to ssh into the RPi, but none of that seem to work. I’m currently a little behind on schedule because of that. In the end, I just kept working on the GPIO communication functions. Debugging sessions will happen next week when we meet up together and have other components ready. For next week, I will be catching up on the work that I needed to do this week.
David’s Status Report for 3-26
In terms of the Raspberry Pi, we still need to consult somebody on how to set it up properly on CMU Secure, but currently, we can work on it at home with an ethernet connection. I have since created a module to create the miner and client to communicate with the mining pools. There is a slight oddity with how bytes and strings are dealt with with Python3, so the client is currently written for Python2 where there isn’t as much of a distinction between bytes and strings, which is easier to understand the data that is sent to the mining pool and the data that we get back from the pool. The mining pool in addition to giving work also gives the previous hash and changes to the difficulty. The last step now is to send the data and receive answers via the GPIO Pins. The decision tree has also been updated to include another attribute of volatility that is currently crudely calculated with an average threshold. Currently, I take the averages of the differences of the high and low prices and divide it by the average of the open and close prices. This in some sense gives a metric of how volatile it was from a generalized mean value. All of these mean values are averaged to get an overall threshold value that the get_data method will use to update the label generation. In addition, the decision tree inference currently conducts a majority vote at the node it traverses to, but the vote has now been changed such that it takes in external variables which currently include shares found and difficulty. Future work involves expanding all of these and especially on Sunday and Monday I want to make the modules to hook up the system so that we can push to have a prototype that doesn’t necessarily have to mine yet, but can at least communicate so that we can set up/hook up everything else during the week.
Team Status Report for 3-26
The overall design remains constant, but the attributes and inputs to the decision tree continue to be changed. The communication between the RPI and mining pool seems to have been isolated and the link in the spotlight now is between the RPI and the FPGAs. We will begin to link up the entire system to test the communication modules to make sure that everything is ready to be hooked up. The largest risk here is just in the modules not working as intended and the management of the risk is exactly as we’re doing, preparing the system and testing it to make sure that it works before moving on.
We had planned on having the FPGA send the number of hashes it completed to the Raspberry Pi in order to get an accurate picture of what the system hash rate is. However, this component is at risk because the timing of when to send this information is still up in the air. We want to minimize all communication with the Raspberry Pi to critical information only. This way, the system is able to scale up to 10+ FPGAs. We intend to mitigate this risk by having the Raspberry Pi calculate this hash rate instead of it being transmitted. Each FPGA has a unique ID and each hashing module on the FPGA has a set numerical bound from which it iterates through nonces. We intend to write software that takes the correct nonce, deduces the bounds that this nonce is in, and calculates the number of hashes the system ran through to reach this nonce.
William’s Status Report for 3-26
This week, I finished the second part of our testing regime by synthesizing every module through terminal as well as using Quartus. I added synthesize commands to our Makefile and updated the FPGA module code such that any unsynthesizable logic was replaced. In particular, the top module took the most time because I was accessing the GPIO pins as a 36 wire block. However, this was causing issues because I needed both input and output functionality within a block. I ended up separating the wires out and only using the five that I needed to implement SPI. In addition, I hardcoded a Bitcoin block header into the code for testing. For now, the FPGA will cycle through all nonces until it reaches one that hashes below the target. Because the block header is preset, the communication aspect of the FPGA modules were not able to be tested.
I am still on schedule because most testing was finished this week.The FPGA side of the communication with the Raspberry Pi is complete but I am waiting on the Raspberry Pi side to be finished.
Next week, I will switch to working on the Raspberry Pi software and making sure that it is able to send and receive data. After this is complete, I can finish the FPGA testing by having a block header be sent over, the FPGA hashes it, and sends the correct nonce back to the Raspberry Pi.
Team Status Report for 3-19
The hashing rate of the FPGA can be increased by having a greater number of hashing modules. However, with each Bitcoin module taking up a cell area of ~13,000 units, we are limited by the number of logic elements on the FPGA. If this is a problem for reaching our target hash rate of 5Mh/s, we will need to optimize the hashing module further. There are additional pipelining techniques that we can use to cut down on the idle time of the hashing module. Additionally, some parts of the block header are being hashed without any modifications. We can eliminate more than a billion redundant hashes by caching this somewhere.
Communication method between FPGA and the web application has not been set and tested yet. For the mitigation plan, we will have the FPGAs send over dummy data to the web app and the web app will then display the data on the website to make sure the communication protocol between these two components are set.
The accuracy of the decision tree is not very high on preliminary tests, but this is with the framework of only 2 attributes both stemming from price changes in the past 10 seconds. The tree was also trained to be rather shallow with the hyperparameter being relatively low. This is only a short term risk and should be bettered later on when we introduce more attributes and deepen the tree to improve inference accuracy.
Caching part of the block header hash will affect how the Raspberry Pi communicates with the FPGA. If we decide to implement this change, it wouldn’t make sense for the Raspberry Pi to send the full 80 byte block header. Instead, out communication protocol will have to be changed to send a 256 bit hash followed by the remaining 36 bytes of the block header. Implementing this change will cut down on our communication costs and allow the system to scale better.
We will no longer be using the stratum mining proxy in tandem with the getwork function to communicate with the bitcoin blockchain, instead we have directly migrated to communicating with mining pools with the stratum protocol. This should make communication more streamlined and understandable while also widening the pool of currencies that we can mine. This does create a overhead where we have to understand the protocol to use it, but we have examples from other available miners to base our implementation off of.
David’s Status Report for 3-19
Since the last status report, many hours were put into the mining proxy that we will not get back. The original plan was to use the same getwork protocol that is used in the Open Source FPGA Miner and bridge the protocol connection with the stratum mining proxy. This path was filled with dependency issues and different work arounds since that miner is meant for Windows and relies on root command, something I don’t have control over on the ECE machines and limited by my own resources locally for tools and dependencies. Even when I got the mining proxy to finally run on the ECE machines, the miner wasn’t able to connect to the proxy, perhaps with some ip address issues, so instead of driving more dead hours into debugging this, we moved on. However, the ultimate reason we decided to no longer continue with this getwork bridging was because this was only going to solve the communication problem for Bitcoin. The same solution was not going to work with Etereum, or any other currency for that matter. Instead, I decided to directly communicate with the stratum protocol, something I guess could be argued that we did in the first place. We didn’t because nobody had experience with the stratum protocol or its parent protocol, JSON RPC. I was able to find some documentation about the protocol and some miner implementations that use the protocol. So at this point in time, we have a very basic communication protocol that can at least receive requests from the mining pool.
Aside from that, I also worked on the decision making process, constructing the decision tree and the scripts necessary to gather the data for training and inference. The decision tree is built upon the historical data we pull from the Binance API. I took the historical klines code from the webapp and pulled as much data as I could to create the training file. The data is formatted currently as price_change_btc, price_change_eth, coin. The coin is ultimately what the miner should have mined. This decision is currently crudely made saying that the miner should mine bitcoin if the price change for bitcoin is up and ethereum otherwise. The model is then used every 10 seconds for inference. Work to be done here is to add more attributes for the decision tree to split on, improve the label generation for training, and process the decision more to not output a coin specifically, but a spread of which coins to mine (probably with some mechanism to prevent it from always predicting the same spread).
Setting up the Raspberry Pi has proven to be a little more problematic than I would have hoped. Setting up the internet with my home wifi is worse than with CMU-DEVICE since there is at least some documentation about how to do it on CMU-DEVICE, my home wifi uses some third party that has no documentation. However, I did try to set it up on campus with the guide, but to no avail. I have another plan to set up the internet since William was able to ssh into the pi, but that will have to wait after the status report. Additionally for work for next week, I hope to finally create the modules to send data from the RPI to the FPGAs to finally start bridging between our different parts. I guess as an administrative thing, as a group we finished the design review document and we each also separately did our ethics assignment.
Some inferences after training:
Sample training data (Data Format):

Lulu’s Status Report for 3-19
For this week I worked on the table that will display cryptocurrency information from the past 24 hours. In addition, the website will now refresh every minute to ensure the current prices are up to date. I tried deploying the website using the Amazon EC2 instance. The instance was setup successfully but I need the final GitHub repository link to deploy the app, which is not yet available because we are working on separate branches individually and haven’t merged into the master branch yet. In terms of schedule, I’m a little behind on the integration between FPGA and the web app. I still need to move the code for the web app from my local computer to the RPi and test the data transmission from the FPGA to the web app. Since we are prioritizing getting connected to the mining pool first, the work for the web app is pushed back a bit. In the meantime, I was working on the SPI send byte function that will take in a byte and turn it into bit format to transmit through GPIO pins. I was also helping to get the historical data for the cryptocurrency and converting it into a format that will be easier to use for the decision tree that we implemented. For next week, I would like to have the FPGA send dummy data and have the web app display on the website to make sure I have the communication method set for these two components. I will also help with other components that we need to finish before the interim demo.
William’s Status Report for 3-19
This week, I finalized a lot of the FPGA modules that will be performing the mining and the communication. I researched an efficient way to perform SHA-256 hashing online and used the Wikipedia article on it to create my own implementation.
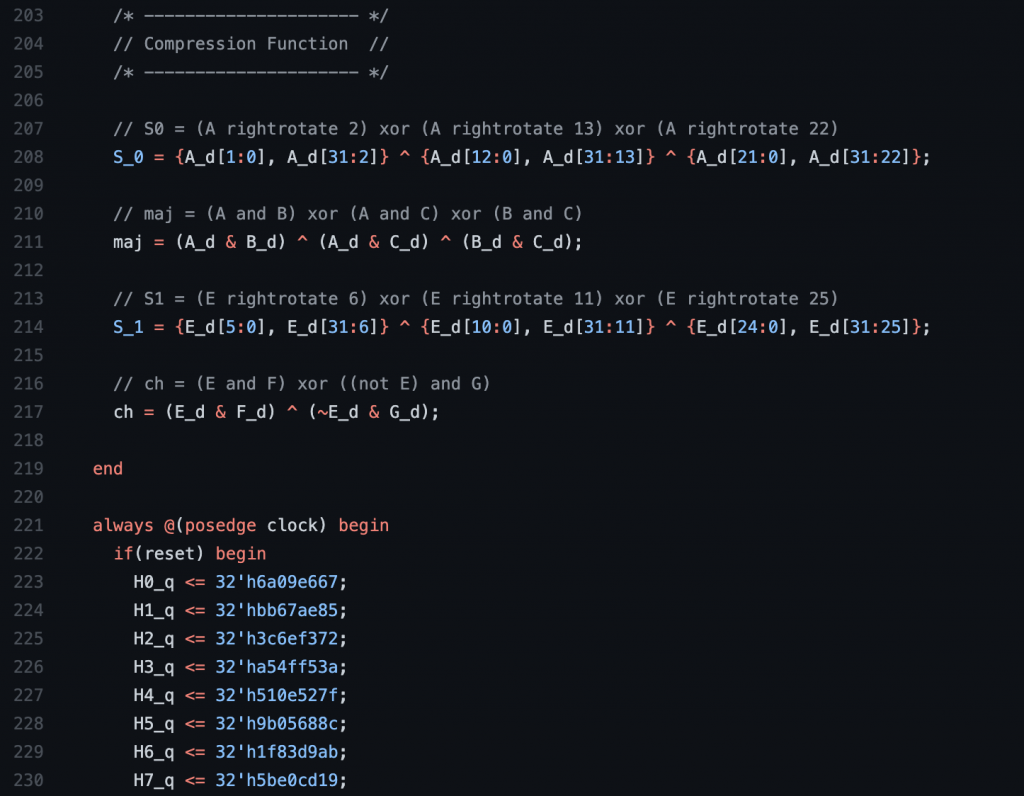
I then tested it with a SystemVerilog testbench to ensure it worked properly. For Bitcoin mining specifically, it requires the hash output to be hashed a second time. Thus, I created a pipeline structure that allows for this second hash to be computed while the first SHA-256 module moves on to the next nonce. This was also tested with an individual testbench.
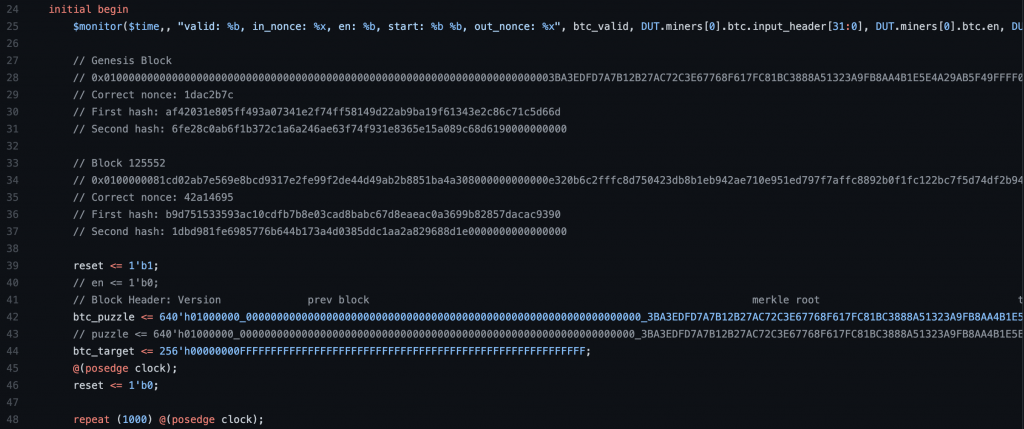
The mining controller is now able to calculate the hash target based on the input puzzle and perform a comparison to check that the hash output is valid. Once the hash is valid, the nonce used to generate this hash is saved. On the communication side of the project, I implemented the FPGA out, Raspberry Pi in, communication module that sends the correct nonce to the RPi through GPIO. It serializes the data and sends the packet along with a header. This was tested as well.
With my work this week and last week, I am now on schedule with my assigned tasks. I caught up on work and will continue to work on the testing portion of the project phase.
Now that all the modules have been implemented and tested through VCS simulation testbenches, I want to move on to the next part of testing with synthesis. Next week I will be doing bug fixing on the FPGA files so that all of them will be synthesizable. Along with this, I will load the final design onto an FPGA and test whether the system as a whole works.