Currently the most significant risk for the audio localization is noise introduced through the USB ports connection using the RaspberryPi. When tested on a local computer, the signals are in the expected range with numerically and visually different outputs for different audio input intensity. However on the RPi, every signal is already amplified and louder audio is indistinguishable from regular audio input due to the resolution range of the Arduino Uno. Lowering the voltage supplied to the microphones to the minimum viable option also doesn’t solve this issue. The contingency plan for this is to perform the audio processing on the computer that hosts the web app. This ties into the system change if we can’t find any other alternative solution for it. No financial cost is incurred due to this change.
Another aspect of the schedule currently worked on is hardware integration of the keypad to the RPi5. I (Jeffrey) am behind on this currently, but am trying to incorporate this with the existing software code that controls the RPS game/logic. We have already adapted the contingency plan, as the current RPS game and logic works with touchscreen display, so we have that prepared in the case that integration with hardware proves more difficult. We haven’t made significant changes to the schedule/block diagram and have built in slack time on tonight and Sunday to ensure that we can continue working on system integration while getting our poster/video demo in by Tuesday/Wednesday night.
Schedule Changes:
Our final 2 weeks schedule is included in the following spreadsheet.
https://docs.google.com/spreadsheets/d/1LDyzVmJhB0gaUmDfdhDsG_PiFwMn-f3uwn-MvJZU7K4/edit?usp=sharing
TTS unit testing:
For the text-to-speech feature, we tested various word lengths to find the appropriate default string to prevent high latency when using the feature. This included one sentence (less than 10 words, ~0.5s), 25 words (~2s), 50 words (~2.5-3s), 100 words (~6-8s) and a whole page of text (~30s). We also tried jotting down notes as the text was read and 50 words was determined to be the ideal length in terms of latency and how much one could note down as text is being read continuously. During this testing, we also noted the accuracy of the text being read to us and it was accurate almost all the time, with the exception of certain words that reads slightly weirdly (e.g. “spacetime” is read as “spa-cet-ime”).
Study Session unit testing:
We tested this by creating multiple study sessions, and then testing out the various actions that can occur. We tried:
- Creating a Standard Study Session on the WebApp and seeing if the robot display timer starts counting up
- Pausing on the robot display and seeing if the WebApp page switches to Study Session in Progress
- Resuming on the robot display and seeing if the WebApp page switches to Study Session on Break
- Ending the Study Session (before the user-set goal duration) on the WebApp and seeing if the robot display timer stops and reverts back to the default display
- Letting the Study Session run until the user-set goal duration is reached and seeing if the pop-up asking the user if they would like to continue or to end the session appears
- If the user clicks OK to continue, the robot display continues to count up
- If the user clicks Cancel to stop, the robot display reverts back to default display, the WebApp shows an End Session screen displaying session duration information.
- Created a Pomodoro Study Session and set break and study intervals on the WebApp, seeing if the robot display starts counting up
- Waiting until the study interval is reached, and seeing if the break reminder audio “It’s time to take a break!” is played
- Waiting until the break interval is reached, and seeing if the study reminder audio “It’s time to continue studying!” is played
TTS + Study Session (Studying features) system testing:
- Create a Standard Study Session, test to make sure that while a study session is in progress (not paused), that the user can use the text-to-speech feature with no issues → user can use the text-to-speech feature, return back to the study session, and also if the goal duration is reached while the user is using the TTS feature, when they return back the pop-up still occurs
- Test that using text-to-speech feature while no Study Session is ongoing is not allowed (if no study session created → redirects to create new study session page, if study session created but on pause → redirects back to current study session)
- Test that using text-to-speech feature during a Pomodoro Study Session is not allowed
- This was a design change as the break reminder sent during a Pomodoro Study Session would interfere with the audio being played while the user is using the text-to-speech feature
Audio unit testing:
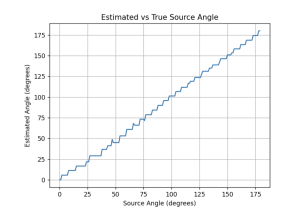
For audio localization simulation, an array of true source values from 0 to 180 have been fed into the program, and have received an output as follows. The general trend it follows is consistent with the expectation, and goal of 5 degrees margin of error. The mean error calculation based on the output turned out to be 2.00 degrees. It is done by calculating the mean absolute error between the true angles and the estimated angles. This mean error provides a measure of the accuracy of the angle estimation. The lower the mean error, the higher the accuracy of the results.
The total time it takes to compute one audio cue is 0.0137 seconds.
This is done by using the time library in python and keeping track of the start and end times of computation.
Audio + Neck rotation testing:
Audio testing on the microphones, signal outputs show a clap lands on the threshold of above 600 with the Arduino Uno’s ADC pin resolution. This value is used to detect a clap cue. This input is being sent to the RPi, and there have been results of inconsistent serial communication latency. This issue is still undergoing more testing. The latency is approximately 20 to 35 seconds to send angle computation from the RPi to the Arduino to change the stepper motor’s position. The most frequently occurring latency of communication is 0.2 seconds or less.
The time it takes for the stepper motor to go from 0 to 180 degrees(our full range of motion) is 0.95 seconds.This value is inline with our expectation of less than 3 seconds for response assuming latency of 0.2 seconds.
The accuracy testing for audio localization accuracy using a microphone is still under progress due to the latency issue, enough data hasn’t been collected to finalize this. This will be thoroughly addressed in the final report.
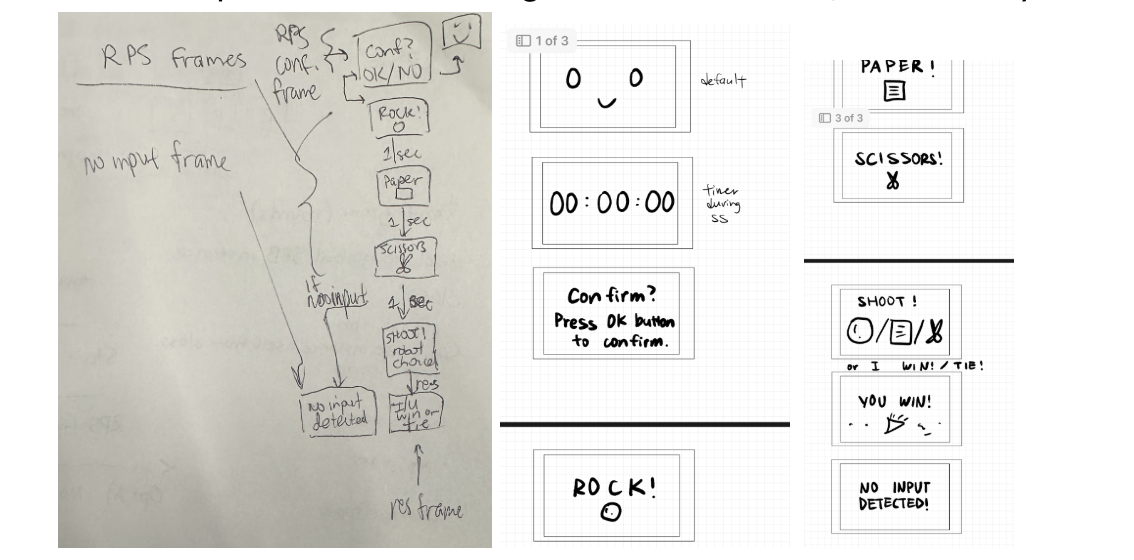
RPS logic unit testing:
Tested individual functions such as determine winner, and ensure register_user_choice() printed out that the right input was processed.
I also tested the play_rps_sequence to display the correct Tkinter graphics and verified that the sequence continued regardless of user input timing. For the number of rounds, I haven’t been able to test the rounds being sent from the Web App to the RPi5, but with a hardcoded number of rounds, I’ve been able to verify that the game follows expected behavior and terminates once the number of rounds is reached, which includes rounds where no input from the user is registered. Furthermore, I had to verify Frame Transitions, 
Where we would call methods to transition from state to state depending on the inputs received. For example. If we are in the RPS_confirm, we would want to transition to a display that would showcase the RPS sequence, once OK is pressed (in this case, OK would be an UP arrow key press on the keypad)
Finally, I had to handle websocket communication to verify that information sent from the Web App could be received on the RPi5 (in the case of handle_set_duration). The next step would be ensuring that I can properly parse the message (in the case of handle_set_rounds) to have an accurate retrieval of information sent from the Web App.
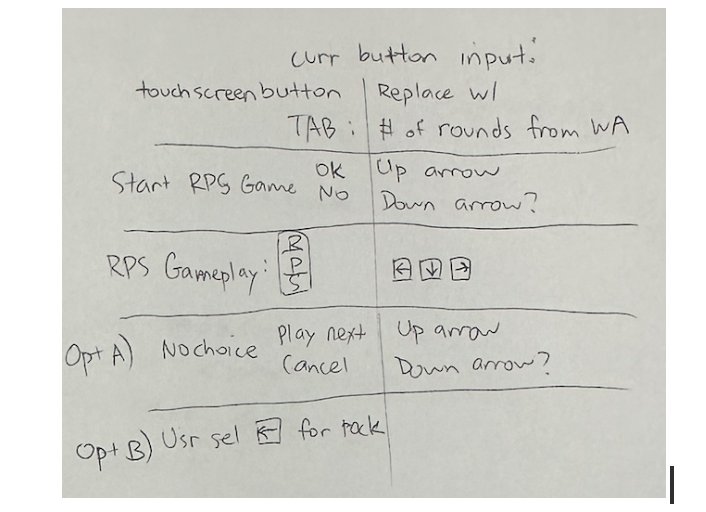
For overall system tests, I’ve been working on the RPS game flow, testing that 3 rounds can be played and that the game produces expected behaviors. I found some cases of premature termination of displaying the sequence or missing inputs, but was able to fix that through iterative testing until the game worked fully as expected utilizing touchscreen buttons. The next step from here would be eliminating the touchscreen aspect and transitioning the code to utilize key pad inputs with evdev (a linux based system that the RPi5 can incorporate). Web App integration also needs to be worked on, for the RPS game. For the study session, Shannon and I have worked on those aspects and ensured that the study session behavior works fully as expected. I would also have to start doing overall system tests on the hardware, which would be the keypad presses in this case. I want to verify that the evdev library can properly detect hardware input on RPi5, and translate that into left -> “rock”, down -> “paper”, right -> “scissors”. In the case of the up key, we would expect different behavior depending on self.state. For instance, in the rps_confirm state, an up press would act as a call to start_rps_game. If we are in the results screen, an up arrow press would act as proceeding to the next round. If we are in the last round of a set of rps games, the up arrow would act as a return home button, with the statistics of those rounds being sent to the Web App.


 Mounted microphones on to the robot’s body
Mounted microphones on to the robot’s body Assembled Body of the robot
Assembled Body of the robot Assembled body of the robot including the display screen
Assembled body of the robot including the display screen


