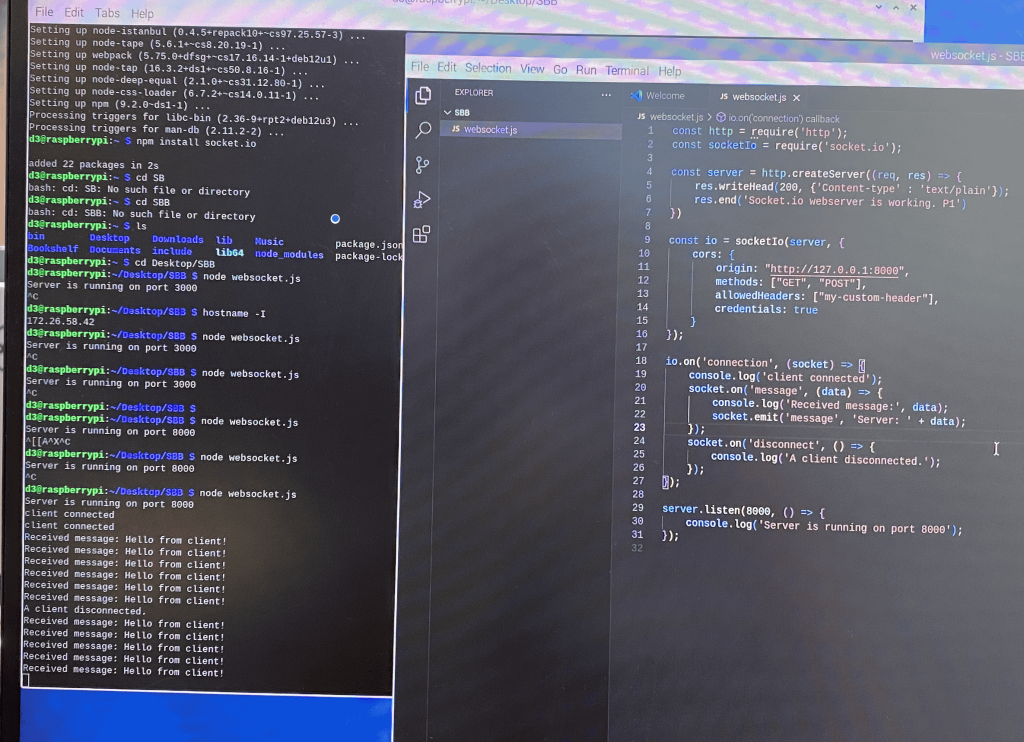
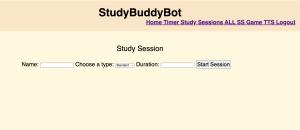
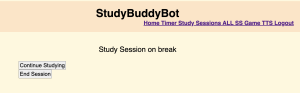
This week, since I was done with everything I was in charge of, I focused my all into helping Jeffrey catch up on his parts. Jeffrey was able to have the Study Session start working, where when a user clicks start session on the WebApp, the robot display screen is able to start a timer. However, he was unable to get the pause/resume or the end session to work. As such, I sat down with him and we worked on these features. I noticed that he had a lot of debugging statements on the robot, which was good, but he wasn’t really logging anything on the WebApp. Following my advice, he did so and we realised that the event was being emitted from the RPi but it was not being received on the WebApp based on the logs. I also noticed that he had a log for when the WebSocket connected on the start but not on the in progress page and so I recommended that he add that. After he added that, I noticed that on the in progress page, the connection log was not appearing and so we waited until it appeared and then we tested the pause/resume button and it worked. Thus, we managed to debug that the issue had to do with latency. We then resolved this by switching the transport to WebSockets from Polling, and that fixed the latency issue. Then, we worked to debug why the End Session on the WebApp was not being received on the robot end. Once again, based on checking the logs, I deduced that it was probably because the events were being emitted wrongly and so the robot event handlers could not catch them. We tried fixing it to receive that event that was being sent by the WebApp instead and it worked – we finished a standard study session! This was done on Wednesday. After this, I took over all TTS and Study Session related work, but Jeffrey will work on the last part of hardware integration with the pause/resume buttons.
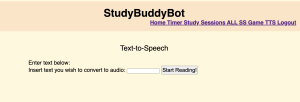
On Thursday, I then integrated my TTS code, and ran into some issues with the RPi trying to play audio from a “default” device and failing. After some quick troubleshooting, I decided to write a config file to set the default device to the port that the speaker was plugged into and it worked! The text-to-speech feature was working well, and there was barely any detectable difference in latency between the audio playing on the user’s computer and on the RPi through the speakers. I tested it some more to make sure it worked with various different .txt files, and when I was satisfied with the result, I moved on to integration with the Study Session feature. I worked on making sure TTS worked only while a study session was in progress (not paused). I wrote and tested some code but it was buggy and I could not get the redirection to work like I desired. I wanted it such that in the case that a Study Session had not been created yet, that the user clicking on the text-to-speech feature on the WebApp would redirect them to the create a new study session and if there was a Study Session that has been created but was on pause, it would redirect them to it. I also wanted to handle the case where if a user was using the text-to-speech feature, and the goal duration was reached, then the user going back to the study session would still trigger the pop-up to occur asking if they would like to continue or stop the session since the target duration has been reached.
On Friday, I continued to work on these features, and I managed to successfully debug them. The text-to-speech feature worked well alongside the Study Session and exhibited the desired behavior I wanted. I then worked on the Pomodoro Study Session feature, which implemented a built-in break for the user based on what they set at the start of the study session. I worked on the WebApp and the RPi, ensuring that the study and break intervals were sent correctly, and then to have it such that the study and break intervals worked, I had to create another background clock that ran alongside the display clock. The standard study session only needed a display clock since the user was in charge of pausing and resuming sessions, but since the pomodoro study session has to keep track of when to pause and resume the session automatically while sending a break reminder audio, it required a separate clock. I wrote and debugged this code and it worked well. This is also when I discovered that the text-to-speech feature could not occur at the same time due to the break reminder being played as well, and so I made a slight design change to prevent this.
Today, I will work on cleaning up the WebApp code, help Jeffrey with any RPS issues that he may face, and start on the final poster.
According to the Gantt chart and the newly linked final week schedule, I am on target.
In the next week I will work on:
- Final overall testing with my group
- Final poster, video, demo and report