
This week I trained a few more versions of our model on recycling datasets. The nice thing about training computer vision models is that they can be validated quite easily with a test dataset, and the training procedure for our YOLO models will output statistics about the model’s performance on a provided test dataset. I have been using this to evaluate the accuracy of our CV system. Here is a confusion matrix from the best run:
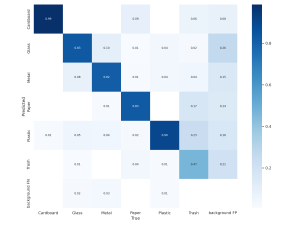
It appears that the model is very good at detecting recyclables, but often confuses trash in the test set for plastic and paper. A solution to this could be to remove trash as a classification output, and instead only classify recyclables, since trash is a very general category, and the sheer variety of items that would be considered trash may be confusing the model. In such a case, we will classify any item that isn’t classified as any recyclable category with high confidence as trash. We will also have to test our model’s performance on trash items, making sure that the model doesn’t recognize them. After I am satisfied with the model’s accuracy on a test dataset, we can move on to capturing images of actual waste with the camera and classifying those. We will test with a variety of objects, with the camera positioned at an appropriate height and angle for where it will sit on the final product. As mentioned in the design report, we want our model’s accuracy to by >90%, so no more than 10% of the items we test should be classified incorrectly (recycling vs non-recycling).
I am also working on figuring out how to deploy YOLO onto the Jetson using the TensorRT engine. If we can convert the model to an engine and load it onto the Jetson, we won’t have to rebuild the engine every time we start up our classification. Once I figure that out, our model will run much faster, and we can do the same procedure if we ever update the model: just convert the new weights into the TRT model engine format, and we will be able to run that. I hope to be able to get that working in the next week, although it’s not a necessity since even without TensorRT it should be more than fast enough.
Schedule is looking on track. Once we get the model deployed, the CV system will be a state where it could theoretically be used for a final demo.