
https://github.com/aakashsell/InSync
Final Project Video
Ben’s Status Report 12/7
The initial part of the week was largely spent getting the final presentation in order (up through Sunday). Helping Mathias plan and practice.
Other progress includes getting two audio streams to work at the same time from two Scarlett Device inputs with some noise issues. The issue now is properly interleaving the stereo channels of the piano microphone input to ensure the levels are balanced and notes are being heard as accurately as possible.
As things wrap up, I am shifting focus towards the deliverables ahead including the final poster, video, and paper. Though I hope so still try and spend some time optimizing the system a bit more.
In reflection, the audio processing seems to mainly pick up only the lower notes of the piano when multiple are played at the same time. Knowing this we could have chosen a cardioid microphone, instead of the ORTF, to record the lower end of the piano with higher accuracy and less noise. Given more time I would have liked to include an active normalization for the audio so the processing was more consistent and we could choose (and know) the noise floor to better filter note detection. I also would have wanted a bit more robust method of demoing. As of now the system is not designed to pick out music from a noisy environment like the demo is set to be which will be a significant issue for getting any accurate live results.
Ben’s Status Report 11/30
The last two weeks have been spent sporadically making improvements from the Interim Demo. Playing with features like the silence threshold seems to have dramatically increased accuracy on the basic music pieces as well as some improvement on Fly Me to the Moon from before.
We also had our first live functional demo with the School of Music musicians and have identified some issues in the data pipeline that have been worked on. The following changes have been made to better pre-process the audio data:
Extending rests – Some rests, also denoted as midi = 0 in our program, left a gap between the start of the rest (silence) and the start of the next note. These have been fixed so that the rest takes up the entire duration between the two notes. This allows for easier and more consistent comparison in the timing algorithm.
Concatenating Silence Values – Any repeated portions of “silence” are now joined into one larger period. This removes extraneous note objects that cause desync in the timing algorithm.
Normalizing start time to zero – The output of any audio processed now begins at time 0.0000 with all other values correctly shifted to match. This ensures all data starts at the expected time since any output from the music XML side expects a start at t=0.
Stitching noise and notes – As mentioned in prior reports there was an issue of. audio spikes causing peaks in the data that were good for timing data but bad for pitch. These peaks have been joined with the note they precede allowing for a cleaner output that still maintains the consistency of the timing data.
Fixing the silence threshold at -45dB – Previously this had been operating under the default value for Aubio at -90dB which detects most onsets. Changing this value reduced the number of onsets and cut out a significant amount of noise. This is still ongoing for experimentation but ideally I could find a way to normalize the audio level so the noise floor isn’t too low (noise gets through) or too high (notes are cutoff or removed).
As usual updates to the DSP test files and main process can be found here
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
The project is on track for the final presentation.
What deliverables do you hope to complete in the next week?
Fixing audio recording issues and preforming more detailed analysis on complex music piece results.
Ben’s Status Report 11/16
This week was spent getting the DSP in a good place for the interim demo. This meant using slightly more complex music (the example being tested this week is Fly Me to the Moon) which has chords, different note timings, and imperfect singing to see if the audio could be properly parsed.
In tandem, features to interface with user input were added. In the final product, these signals will ideally come directly from the web app but, for now, can be directed through command line inputs. The program can process existing sound files or attempt to record from scratch, save, and process the audio. This allows the program to mimic the full functionality we hope to have once all parts are combined.
Time was also spent manually slicing and cleaning up audio files from the recording sessions which are located in the Recordings folder of the project. This was necessary since each take needed to be broken up seperately and the vocal and piano tracks needed to be isolated into their own files respectively.
Aubio is producing more audio events than there are notes in the piece. This makes sense, as deviations in playing (particularly singing) seem to cause multiple notes to be generated. Remove erroneous data from the stream (i.e. midi values that correspond to octaves not being reached). This removes any of these spikes but also results in some missing data. More testing is needed to determine which spikes are just noise and which are valid events (with wrong pitch data).
In addition, a method of “pitch stitching” is in progress but needs work. This would combine sequential pitches of very close or equal values into one event. So far this has yielded mixed results with increasing error as the complexity of the piece increases.
Updates to the DSP test files and main process can be found here
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
The project is on track for the interim demo this upcoming week.
What deliverables do you hope to complete in the next week?
Time will largely be spent working towards the demo and then refining the pitch detection and timing output even more.
Ben’s Status Report 11/9/24
This week, I was not as productive as I would have liked do to factors outside of my control, however progress was made. As it stands, the audio processing component successfully takes in a basic audio file, and produces a correctly formatted, and correctly populated output. Seen below, the output is broken into three values per row in the form:
[midi value, start time (seconds), duration (seconds)]

This was generated after running a basic audio test file created by the midi output of this simple score:

It can be seen, however, there is some slight error in the process of determining exact duration as is expected. It can be seen that all notes started almost exactly 0.5 seconds after each other. Since the audio file was simply a uniform midi output, the duration of each note should be the exact same though the test yields some variance. Duration is a difficult value to accurately assess as it requires primitively determining the silence threshold, the point at which notes are considered not-playing or “silent.” In this case, the value is set at -40dB which is the standard value for the Aubio library and other recording standards.
All files have been added to the DSP folder in the group git linked here.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
I am behind schedule due to external circumstances. With that being said, I have concentrated my efforts and am making back up that time but have accounted for delays by using up some of the slack planned out from the beginning of the project
What deliverables do you hope to complete in the next week?
The system is in the early stages of integration and will hopefully be able to run in a limited demo mode by the end of the week. This would look like running the system with a very basic score and midi audio.
Ben’s Status Report 10/26
This week, I was able to connect a live pipe between the Scarlett audio interface and Aubio to generate a real-time stream of pitch values . From initial testing I was able to generate a mapping to understand the pitch value output. It follows that middle C (C4) maps to a value of 60, with every semi-tone increasing or decreasing the value by one point. I did notice some potential issues from the live audio testing.
- Any elongated or plosive consonants (“ssss”, “ttt”, “pppp”) caused a spike into the 100+ range which is out of the bounds we are considering for expected pitch as it would put the sound in and above the 7th octave (above what a piano can play). Accounting for that is important but since it is so high, it might be easiest to simply ignore values outside the expected range.
- Chords behave abnormally. When two notes or more are played simultaneously, the output value was either lower than any of the pitches played or simply read “0.0” which is the default no-input or error value output. I believe there is a specific way to handle chords but this requires further digging into the documentation.
- Speaking seems to consistently generate an output of “0.0” which is good, however some quick transitions from speaking to singing yielded mixed results. Sometimes the pitch detection would work immediately and other times it took a second to kick in.
- Lastly, the pitch value provided has a decimal that corresponds to the number of cents each pitch is off by relative to the fundamental pitch. Accounting for notes that are within +/- 0.5 from a just pitch will be important. Vibrato varies from person to person but for me, at least, it seemed to be within that tolerance which is a good thing.
Is your progress on schedule or behind? If you are behind, what actions will be taken to catch up to the project schedule?
I am just about on schedule. This is an ongoing learning progress but being able to sing live or play live and have a pitch value output is promising.
What deliverables do you hope to complete in the next week?
I hope to refine and create a more robust output that takes the average pitch over a short duration to create a pitch event list that is more parseable for the timing algorithm.
Ben’s Status Report for 10/5
This week, my focus was attempting to set up a connection between my existing audio interface (Scarlett Solo) and a python script that could process the input. I found three Python libraries to support this.
Firstly, PyAudio which is one possible route for input/output for our system. It can read existing sound files (like .wav) which is useful since we are starting by piping in recordings instead of live audio at first. It also has basic streaming capabilities for a possible shift to live audio input.
A second option I researched for I/O is SoundDevice. Similar to PyAudio it can parse an existing music file and/or stream in real-time audio. It works in conjunction with numpy and has existing starting templates for various projects found here.
Aubio is a library with pitch onset, duration, and separation routines; Audio filtering, FFT, and even beat detection. All of these features are essential components to our sound processing workflow.
Using templates from these libraries I made a basic, untested python script as a starting point.
In terms of scheduling, I am slightly behind as I expected to be working on the filtering component starting this week. I have realized that the event list generation can and should happen first as it goes hand in hand with the audio path creation. As such the scheduling has been changed to start that this upcoming week with filtering being pushed back until week ten as ensuring a working pipe for MVP needs higher priority.
By the end of next week I hope to have a python script that can take in an audio file and break it down into a tuple structure that contains (pitch, onset time, and a guess at duration). For my purposes I do not expect the generated list to be accurate, instead focussing on producing one to be tested in the first place. I’d also like to have a partial method of reading in input from a Scarlett audio interface. That is to say, a script that successfully transfers some data from the microphone into a buffer I can parse. I imagine that the live connection will take more time and may need to be shared over the next week as well, the schedule has been updated to reflect this (See group status update, Conversion Algorithm subsection).
Ben’s Status Report for 9/28/2024
This week I continued conversations with Professor Roger Dannenberg regarding the approach to the digital signal processing (DSP) required for the project. We reached the conclusion that a FPGA may unnecessarily complicate the design as many of the existing infrastructure for DSP exists in software-land.
Additionally, I lead a recording session in collaboration with CMU School of Music students to collect our first batch of audio data for the project. From this I generated both answers to some of our qualitative timing metrics and more cases we need to consider or test for.
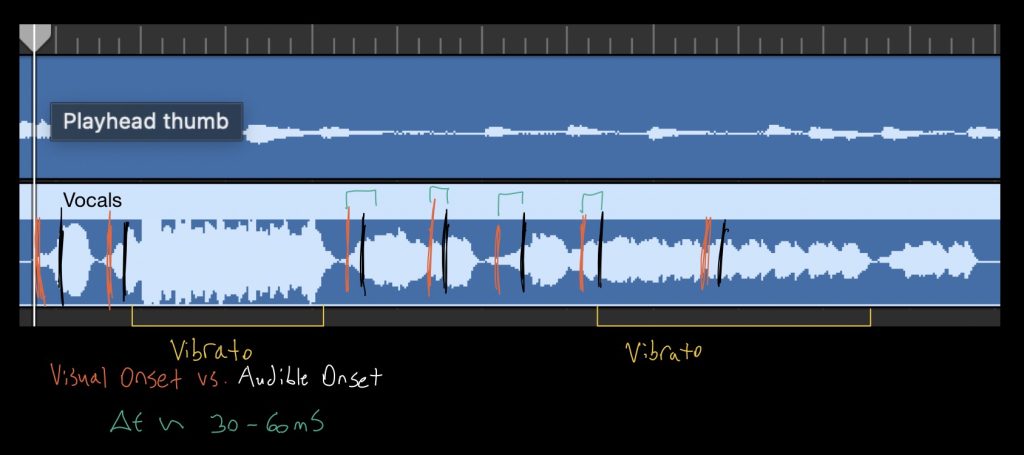
In regards to audio signals, there is both a visual/physical onset, and a audible onset. The physical onset is the beginning of an articulation; where the instrument first begins to produce a sound. The audible onset is the point at which the note can first begin to be heard by the human ear during playback. From the initial measurements, the delay from the visual onset to the audible onset for the vocalist was within the 50-100mS range. This is important to consider since music is based solely on the audible perception of its waves.
There are a few approaches in consideration of pitch. The first, Dynamic Time Warping (DTW) attempts to synchronize two unsynchronized audio streams like our use case. This could be used in the production of feedback as it will give an idea of what portions needed to be dynamically changed to resynchronize the two musicians. Fast Fourier Transforms may also need to be used to attempt to isolate pitches and separate chords. These are both best done in software as part of DSP libraries. Research is ongoing.
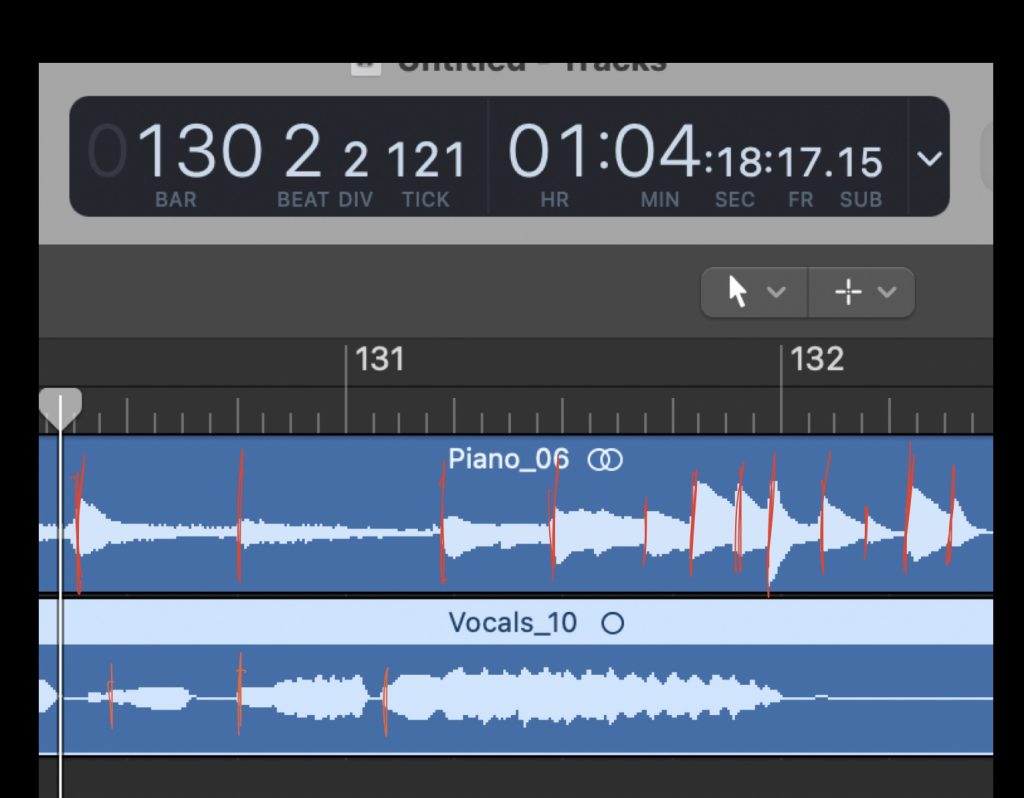
Something else to notice from our data is that the piano articulations are much more uniform in shape (triangular) relative to the more oblong and noisy vocal track. This confirms our suspicions about which instrument (voice) will be more of a challenge to properly filter and process. An additional consideration is that consecutive notes do not necessarily have a clear separation in the vocal track like they do in the piano track. This will require further research, but motivates an algorithm that listens for the onset of note clusters rather than their ends since that distinction is much more difficult to quantify.
Overall it would seem that we have a bit more a buffer with latency since the onset gap is larger than expected. However, I don’t expect this to be an issue using software as there are only two input steams.
Ben’s Status Report for 9/21/24
This week, I spent much of my time researching the gaps in my knowledge regarding the planned hardware and audio processing we require for our project. I watched multiple hours of high-level discussion of similar real-time audio processing projects. I learned about audio codecs and their utilization of ADCs. Finally, I contacted field experts after generating a list of technical questions from my learning. The hope is that with some conversation, I can be pointed in the right direction in terms of how to go about the audio processing and gain a better idea of what is feasible, given our time frame. Looking forward to next week, I would like to finish the high-level design of the hardware data path and have a specific FPGA selected for the project to maintain the schedule we have planned.