
This week I continued conversations with Professor Roger Dannenberg regarding the approach to the digital signal processing (DSP) required for the project. We reached the conclusion that a FPGA may unnecessarily complicate the design as many of the existing infrastructure for DSP exists in software-land.
Additionally, I lead a recording session in collaboration with CMU School of Music students to collect our first batch of audio data for the project. From this I generated both answers to some of our qualitative timing metrics and more cases we need to consider or test for.
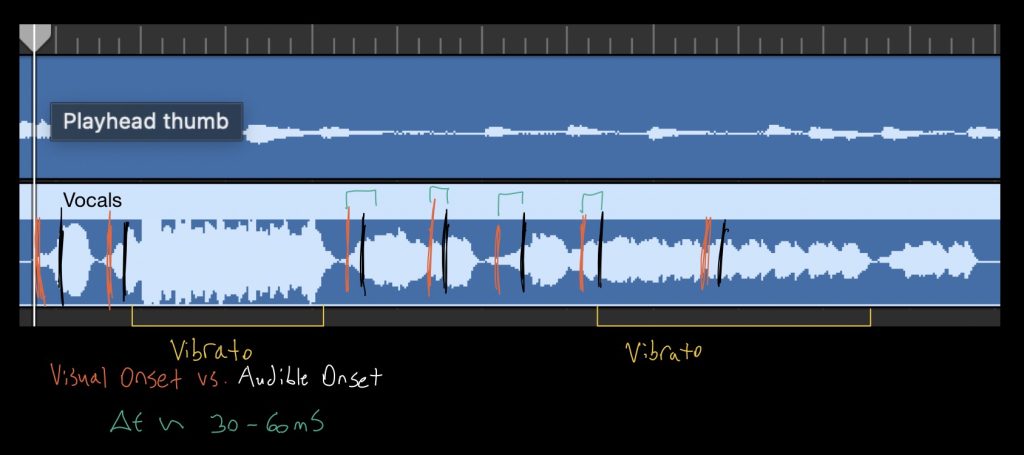
In regards to audio signals, there is both a visual/physical onset, and a audible onset. The physical onset is the beginning of an articulation; where the instrument first begins to produce a sound. The audible onset is the point at which the note can first begin to be heard by the human ear during playback. From the initial measurements, the delay from the visual onset to the audible onset for the vocalist was within the 50-100mS range. This is important to consider since music is based solely on the audible perception of its waves.
There are a few approaches in consideration of pitch. The first, Dynamic Time Warping (DTW) attempts to synchronize two unsynchronized audio streams like our use case. This could be used in the production of feedback as it will give an idea of what portions needed to be dynamically changed to resynchronize the two musicians. Fast Fourier Transforms may also need to be used to attempt to isolate pitches and separate chords. These are both best done in software as part of DSP libraries. Research is ongoing.
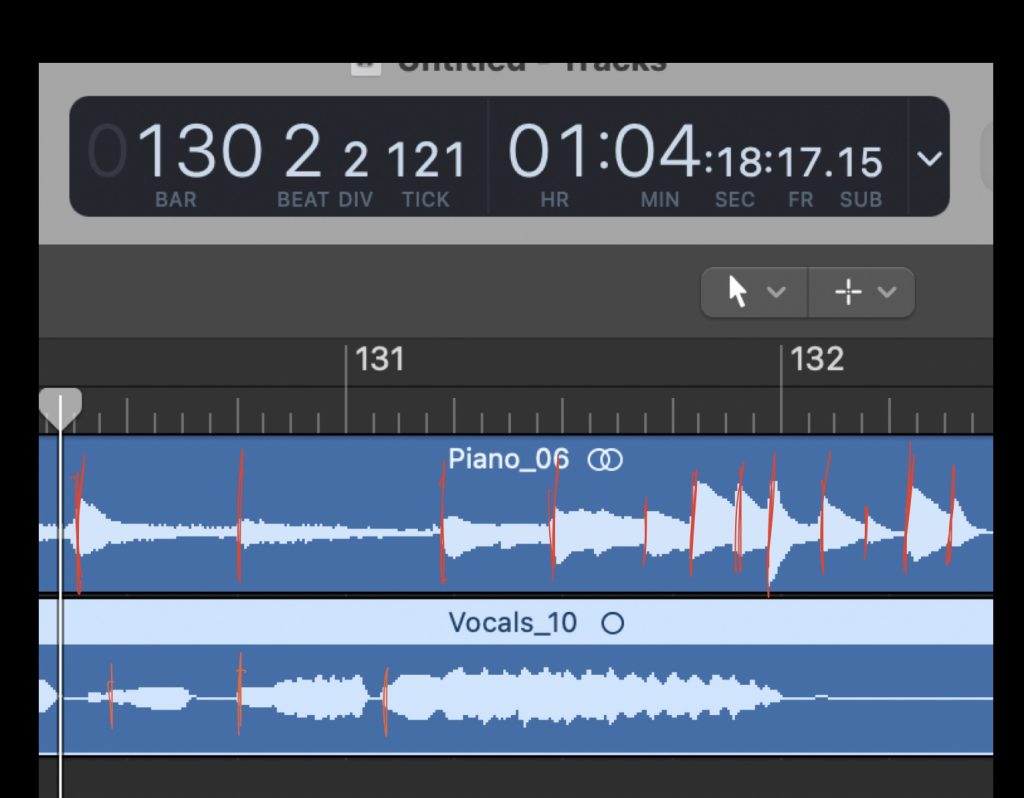
Something else to notice from our data is that the piano articulations are much more uniform in shape (triangular) relative to the more oblong and noisy vocal track. This confirms our suspicions about which instrument (voice) will be more of a challenge to properly filter and process. An additional consideration is that consecutive notes do not necessarily have a clear separation in the vocal track like they do in the piano track. This will require further research, but motivates an algorithm that listens for the onset of note clusters rather than their ends since that distinction is much more difficult to quantify.
Overall it would seem that we have a bit more a buffer with latency since the onset gap is larger than expected. However, I don’t expect this to be an issue using software as there are only two input steams.