Through the past two weeks or so, I have been finishing up the last touches with the CV, gathering testing data, and integrating with the rest of the system. The biggest change to the CV was to transform the image to account for images that are not perfectly in-line with the board. This added additional time to the classification, since I need to essentially run through the character recognition first to identify corners to be used in the transformation, then re-recognize characters on the new image while mapping them to their locations. While this certainly added significant time to the functionality, the CV is far more robust and character location mapping seems to be very accurate. This was shown through a 100% location accuracy through 5 testing boards after making this change.
I’ve also made a few modifications to some of the tiles that were being misclassified. We decided to put a diagonal line through ‘O’, which was being misclassified often as ‘D’. I have so far seen 100% accuracy with these characters after this change. Overall, OCR accuracy seems to be around 95% percent, but I am still in the process of gathering some final data.
Another change was the decision to require all 4 corners of the board to be identified before attempting to classify and locate them. Before, if not all 4 corners were found, I was trying to use 2-3 identified corners to estimate the locations of the characters as accurately as possible, however, this did not result in acceptable location accuracy. We have decided requiring all 4 corners identified (which seems to not be an issue so far) is better than mislocating words, which could significantly harm the game state.
Lastly, I’ve been working with Jolie and Denis to get our system integrated together. For example, we recently finished implementing the functionality of taking an image on the RPi and running it through the OCR before sending it to Jolie’s scoring code.
As we enter the final week, we will finish integrating, gather testing data, and finish our poster, video, and report.
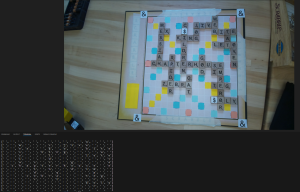
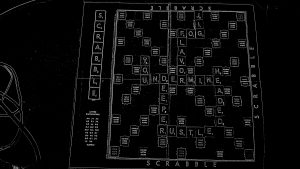
Below is one result from testing. The console output is characters identified and their locations. In this test, all characters were correctly identified and located, despite the input image being far from ideal.