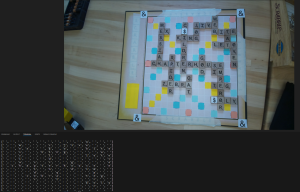
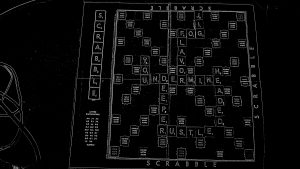
We have integrated most of our system (Cody’s computer vision model, Denis’s MQTT and user app, and Jolie’s game state tracker and board checker). We decided to take out the main user display board as it seemed redundant considering we can just flash the validity and score to the player after the “Check” button is pressed. With less than one week left, we are looking solid and close to completion. We still have some testing to do including our user study in addition to the video, poster, and final report to finish.
Tests Completed:
- MQTT Data size test: We tested varying sizes of data packets to see their effect on the latency of communication. We decided to use packets of less that 300 Bytes as a result
- Individual CV letter tests: We tested the accuracy of identifying individual letters in order to see which ones were the least consistent. This led to us adding additional marks to the I and O letter tiles
- Size of Database vs accuracy and time: we tested varying database sizes and their impact on the CV accuracy, as well as how long that it took to process the images. Ran 3 tests, one with a full, a half and a minimal version of the database. The tradeoffs were as we expected, the larger the database, the more accurate but the slower it was.
- Testing scoring and validity: We tested a variety of different word locations and valid/invalid words on static boards, this led us to being certain that our sub functions worked