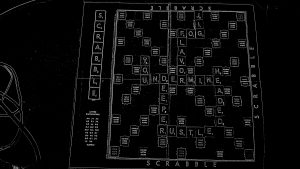
This week, I primarily worked on the character recognition software. After some research, I found it was likely the best to first run some preprocessing to convert the image to black and white, then isolate and draw onto the original image the contours of each character for better performance of the OCR. Currently, most characters are able to be recognized, but some without curves (L, T, I, etc) are proving more difficult. I plan to further tune some of the preprocessing and contour recognition to improve this. Once the individual characters are identified, I will work on the logic to build adjacent characters into words and eventually map them to the board for score calculation. Additionally, I assisted my team with the design report.