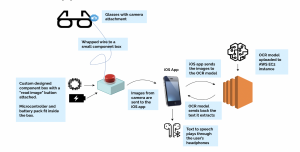
The most significant risks right now are regarding integration and testing. For integration, as we finalize our ML models we don’t have as much time as we might want when it comes to debugging. This week we have been running into many issues with integrating our systems, whether it has to do with incompatibilities, file path issues, or more. We will be working hard throughout the weekend and until the demo in order to finalize our integration. Along with this risk comes the risk of not having enough testing. If we don’t finish our integration in time, we will not be able to conduct thorough testing of our complete system, and also won’t be able to conduct thorough user testing. As mentioned last week, if we cannot test tomorrow we will likely have to test during the demo on Monday so that we can include our results in the final report.
We have not made any changes to the design of our system since last week, and have not updated our schedule.
For our latency tests, we measured the time between the button press for starting/stopping audio, and the result. We took 10 trials and averaged the results. For the start button latency, we measured an average of 5 seconds, and for the stop button latency, we measured an average of 60 ms. It is worth mentioning that these latencies are dependent upon the network delay and traffic at the time.
For our weight and size measurements, we simply used a scale and a ruler. The weight of our attachment was 86 grams, and the size was 76 mm by 42 mm by 37 mm.
For battery life, we measured a minimum battery life of 5 hours when the device was being used constantly. This was after testing the battery on 5 separate occasions.
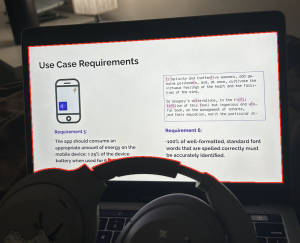
For our graph detection ML model, we gathered around 2000 real images of lecture slides which we split into a training and validation set. The validation set had a size of about 100 images and our unit tests involved testing whether the graph detection model was able to detect good bounding boxes around graphs in the slides. To measure the accuracy of this, we used mean intersection over Union as a metric – calculating the overlap / total area of the predicted and true bounding boxes from what we labeled. We found that all graphs were accurately detected (100% detection rate) and the mean IOU was about 95%, so bounding boxes were pretty good about capturing the whole graph.
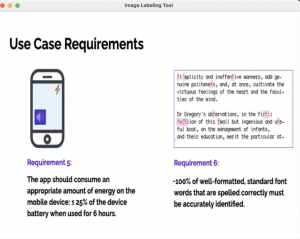
For our slide matching ML model, unit testing involved taking a validation set of 110 images from the images of slides we captured with our device in TechSpark. We then tested both components of our slide matching system. First, we tested the detection of bounding boxes around the slide number on the slide. These numbers were detected with 100% accuracy. We then took the cropped images of the slide number boxes and then ran a second model on them in which we did preprocessing and then classification of each digit. These tests revealed an accuracy of 73%, so our total accuracy for slide matching from unit testing is 73%.
For our graph description ML model, our unit tests involved measuring the mean accuracy in terms of token-to-token matching with the reference descriptions. We did this on a set of about 75 graphs out of the graphs we extracted from real slides, and this revealed an accuracy of 96%.