- What are the most significant risks that could jeopardize the success of the project?
This week, the team focused on wrapping up and presenting our design review. We also spent some time experimenting with the Jetson and individually researching approaches for our respective phases. This early exploratory work has set us up nicely to begin writing our in-depth design report and finalize our bill of materials to order parts.
Based on our research, we have also identified some further potential risks that could jeopardize the success of our project. While researching the classification phase, we realized that the time spent training iterations of our neural network may become a blocker for optimization and development. Originally, we had envisioned that we could use a pre-trained model or that we only needed to train a model once. However, it has become clear that iteration will be needed to optimize layer depth and size for best performance. Using the equipment we have on hand (Kevin’s RTX 3080), we were able to train a neural network for 20 epochs (13 batches per epoch) in around 1-2 hours.
2. How are these risks being managed?
To address training time as a possible blocker, we have reached out to Prof. Mukherjee to discuss options for an AWS workflow using SageMaker. Until this is working, we will have to be selective and intentional about what parameters we would like to test and iterate on.
3. What contingency plans are ready?
While we expect to be able to use AWS or other cloud computing services to train our model, our contingency plan will likely be to fall back on local hardware. While this will be slower, we will simply need to be more intentional about our decisions as a result.
Based on initial feedback from our design review presentation, one of the things we will be revising for our design report will be clarity of the datapath. As such, we are creating diagrams which should help clearly visualize a captured image’s journey from sensor to text-to-speech.
4. Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)?
One suggestion that we discussed for our design review was the difference between a comfortable reading speed and a comfortable comprehension speed. Prof. Yu pointed out that while we would like to replicate the performance of braille reading, it is unlikely that text-to-speech at this word rate would be comfortable to listen to and comprehend entirely. As a result, we have adjusted our expectations and use-case requirements to take this into account. Based on our research, a comfortable comprehension speed is around 150wpm. Knowing this metric will allow us to better tune our text-to-speech output.
5. Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
Placing an upper limitation on the final output speed of translated speech would not incur any monetary or performance costs.
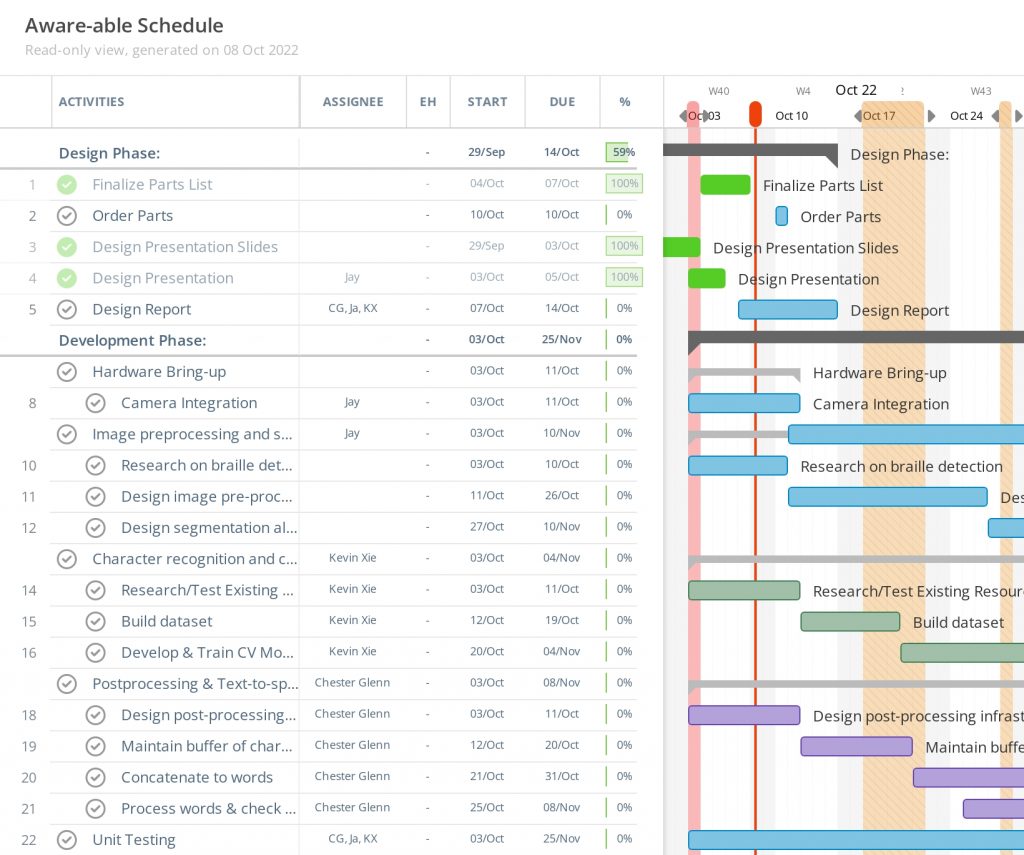
6. Provide an updated schedule if changes have occurred.
Based on our Gantt chart, it seems that we have done a good job so far of budgeting time generously to account for lost time. As such, we are at pace with our scheduled tasks for the most part. In fact, we are partially ahead of schedule in some tasks due to experimentation we performed to drive the design review phase. However, one task we forgot to take into account in our original Gantt chart was the Design Report. We have modified the Gantt chart to take this into consideration, as below: