What are the most significant risks that could jeopardize the success of the project?
One issue we ran into this week was with connecting the eCAM50 MIPI CSI camera that we had expected to use initially. Due to unforeseen issues in the camera driver, the Jetson Nano is left in a boot loop after running the provided install script. We have reached out to the manufacturers for troubleshooting but have yet to hear back.
Looking at the feed from our two alternative cameras, the quality of video feed and the resulting captured image may not exhibit optimal resolution. Furthermore, the IMX219 camera with its ribbon design and wide angle FOV is highly vulnerable to shakes and distortions that can disrupt the fixed dimensional requirements for the original captured image, so further means to minimize dislocation should be investigated.
How are these risks being managed?
There are alternative cameras that we can use and have already tested connecting to the Nano. One is a USB camera (Logitech C920) and the other is an IMX219, which is natively supported by the Nano platform and does not require additional driver installations. Overall, our product isn’t at risk, but there are trade offs that we must consider when deciding on a final camera to use. The C920 seems to provide a clearer raw image since there is some processing being done on-board, but it will likely have higher latency as a result.
We will be locating the camera in a fixed place(rod,…) along with creating dimensional guidelines to place the braille document to be interpreted. Since the primary users of our product could have visual impairments, we will place physical tangible components that will provide guidelines for placing the braille document.
What contingency plans are ready?
We have several contingency plans in place at the moment. Right now we are working with a temporary USB camera alternative to guarantee the camera feed and connection to the Nano. In addition, we also have another compatible camera that is smaller and has lower latency with a small quality trade off. Finally, our larger contingency plan is to work with the Jetson AGX Xavier connected to the wifi extension provided by the Nano, and mount the camera for the most optimal processing speeds.
Were any changes made to the existing design of the system (requirements, block diagram, system spec, etc)?
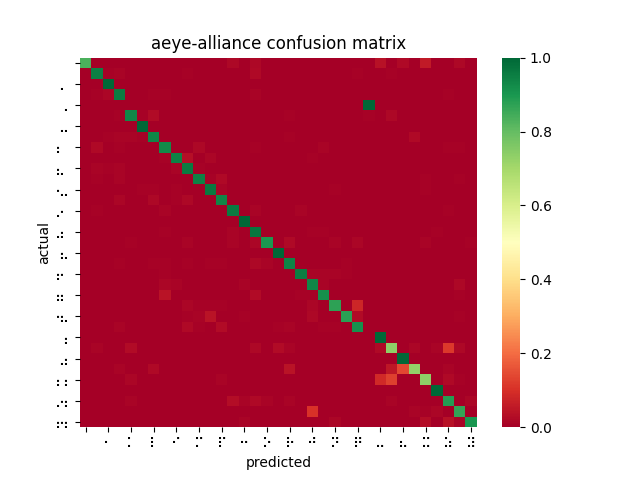
Since our last report, no significant changes have been made to the system design of our product. We are still in the process of testing out the camera integrated with the Jetson Nano, and depending on how this goes we will make a final decision as we start to finalize the software. In terms of individual subsystems, we are considering different variations of filtering that work best with segmentation and the opencv processing, as well as having the classification subsystem be responsible for concatenation to simplify translation of the braille language.
Why was this change necessary, what costs does the change incur, and how will these costs be mitigated going forward?
Since we did not change any major sections of the system design, we do not have any costs associated currently. Right now, we are prepping for the interim demo and if everything goes well we will be in solid form to finish the product according to schedule. Individually, the work will not vary too much and if needed can be shifted around when people are more accessible to help. At this stage in the product, most of the software for our individual subsystems has been created and we can start to work more in conjunction with each other for the final demo.
Provide an updated schedule if changes have occurred.
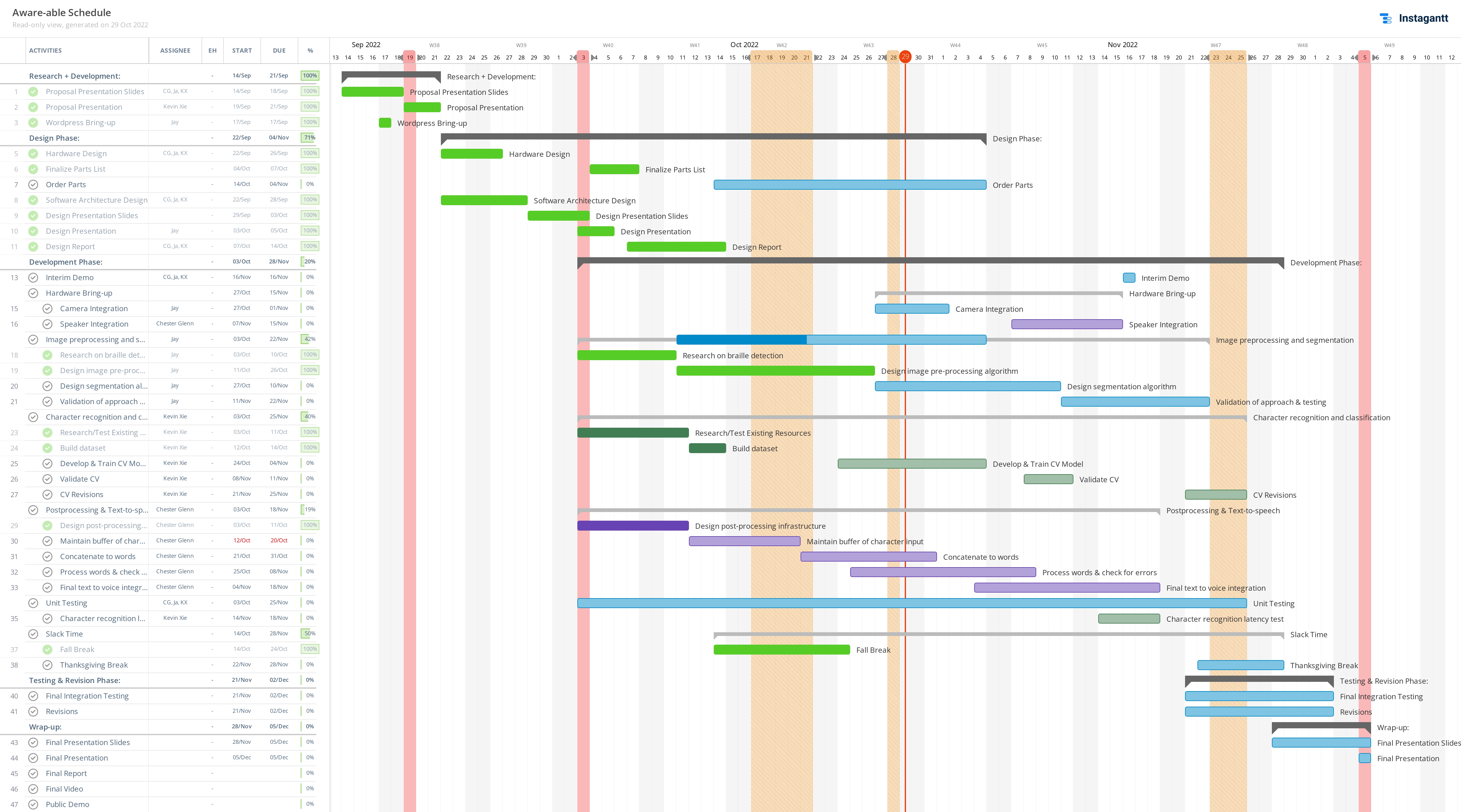
Since we had been working based off of the deadlines on the Canvas assignments, our Gantt chart was structured under the impression that Interim Demos would take place during the week of Nov. 14. We have since changed our timeline to match the syllabus.