
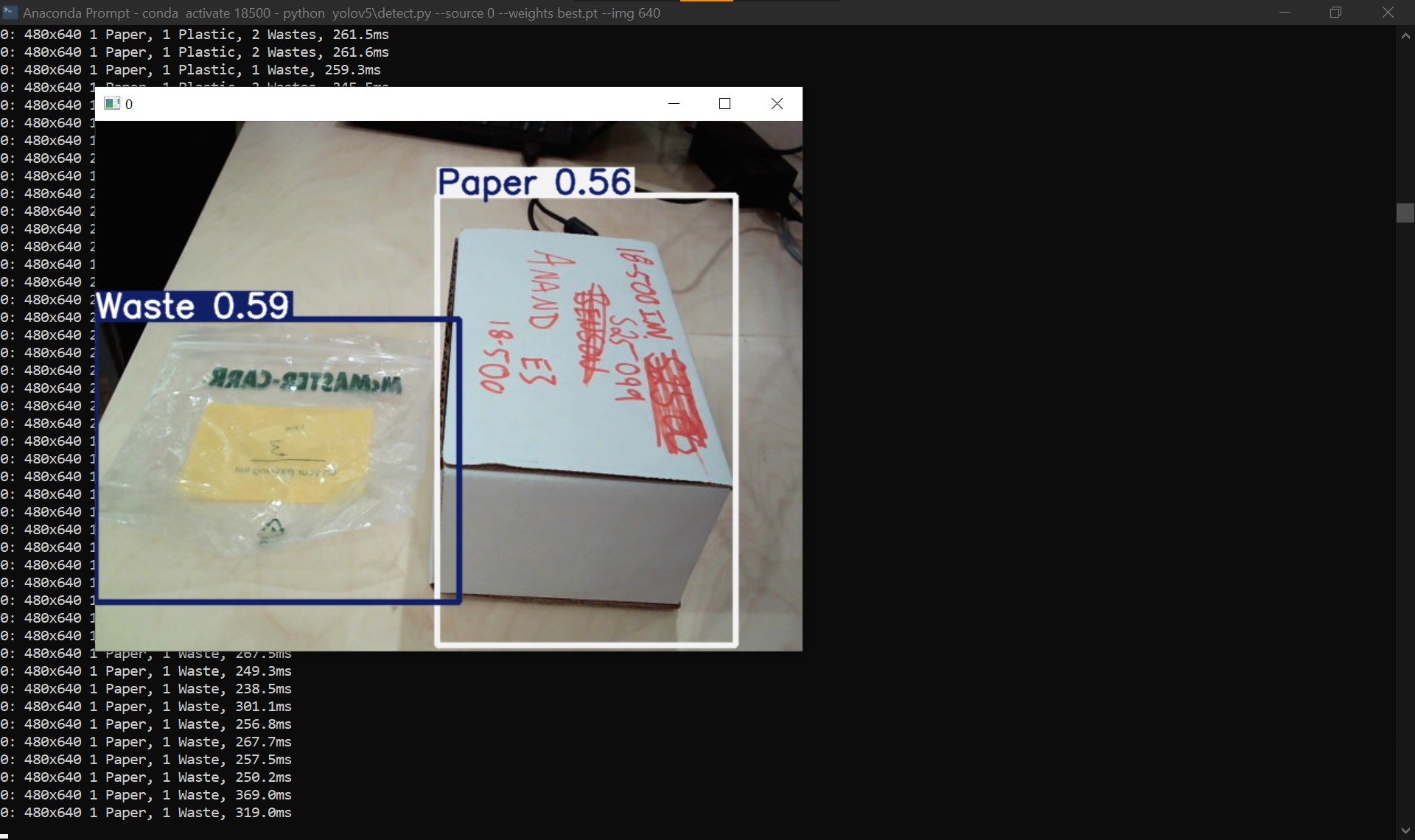
Over the past week I worked alongside the rest of the team on wrapping up our final presentation, in addition to working on the final integration of the subsystems. For the final presentation, I worked on timing the latency in addition to conducting multiple trials to measure the model’s accuracy in plus the time it takes the cohesive script’s to detect and run inference on a singular object. In terms of implementation, I managed to interface successfully with the ramp through the main script that handled object detection, but my progress was impeded by inconsistent turning of the ramp. As mentioned in the Team Status Report, the issue was caused by mechanical failure, though I initially had suspicions it may have been a servo issue. Between now and the demo, I hope to iron out any last quirks with interfacing with the servo, which should have the system ready for its final testing prior to demo day. Additionally, I will fine-tune our YOLO model on the TACO dataset (unused at the moment in favor of the research paper dataset) to see if that improves inference results in any way.
Mohammed’s Status Report for April 19th, 2025
This week I worked on multiple parts of my domain in the project, including the camera dynamics, running CUDA, and improving our YOLO model. Furthermore, I worked alongside the rest of the team in the overall integration of all the project’s subsystems.
My week started off with running our interim demo’s inference script on CUDA since I got GPU acceleration working last week. While I wished it were as simple as running the script, that of course was not the case. As a reminder, I had trouble compiling the Jetson libraries necessary for CUDA support on widely supported Python versions like 3.8, so I opted to reflash the Jetson with an image that contains the necessary libraries pre-installed, albeit at the price of sticking to an older Python version. Unsurprisingly, this led to library dependency issues as some of the libraries used in our interim demo did not support our downgraded Python. As a result, I had to also downgrade to an older version of YOLOv5, which then caused issues with importing the model as that was fine-tuned on the latest version. Long story short, I had a few painful hours of re-exporting the model and modifying the script to accommodate any differences in the new model’s behavior, but all is well that ends well as I got GPU acceleration working with YOLOv5. Compared to running inference on the CPU, CUDA inference is unsurprisingly smoother, which should aid us in meeting our inference time use case requirement.
With GPU acceleration working, I then moved on to configuring the Oak-D SR camera. I learned the hard way that a high bandwidth USB 3.0 to USB type C cable is necessary to properly interface with the camera. I followed the company’s documentation for setting up the camera and running their demo Python scripts, which had variable success from the get-go as only the grayscale ones would work. After some tinkering I found out that initializing the SR’s RGB camera’s was different than the remaining models (or at least I assume), so I adapted the new initialization steps and got the demos working in color that way. I mainly tinkered with the camera control’s demo, which places you in a sandbox setting where you could fine-tune the many settings of the camera to your liking. Additionally, I tried implementing a quick script for depth detection as that would be helpful for detecting nearby objects on the belt, but with variable success. Note that all the aforementioned was done on my laptop.

Unfortunately, getting the camera to work on the Jetson was not a cake walk, primarily because its power and memory usage caused the Jetson to outright shutdown due to stress. Initially I had the camera function as a generic webcam using a UVC (USB Video Class) Python script before connecting to it using our interim demo script. To place less strain on the Jetson, I switched to handling everything in one script in addition to adding further optimizations like installing a less memory intensive desktop interface, and optimizing my model’s weights to short floats (from floats). The camera feed was stable since, although slightly choppy. The bummer is despite all I have done to get the Oak-D working, our model’s performance with it was inferior to the generic webcam, likely due to color differences. I tried fine-tuning the camera output as much as possible to optimize our accuracy to what it was before but with variable success. So we decided to stick with the generic webcam used for the interim demo. I optimized the camera’s feed to reduce the glare on object’s, an issue that made certain objects undetectable, using the Video4Linux2 interface. We hope to revisit using the Oak-D SR in addition to its depth mapping if time permits.
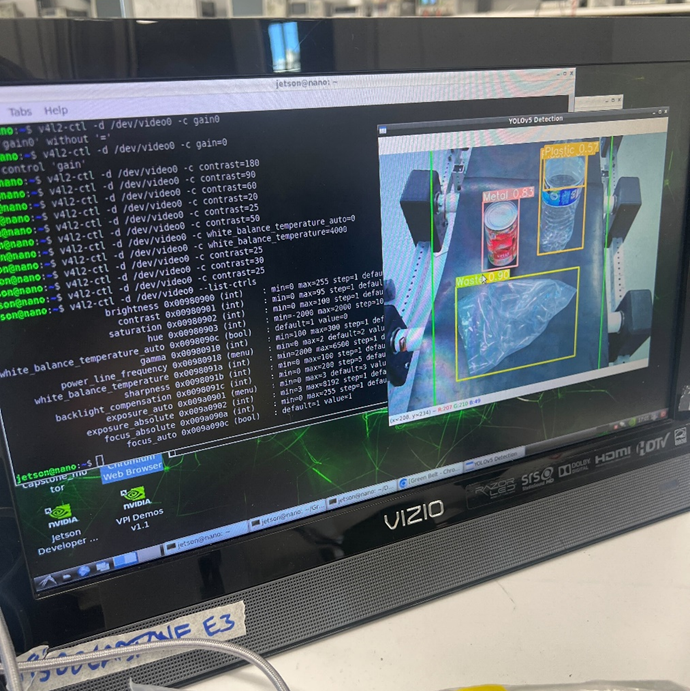
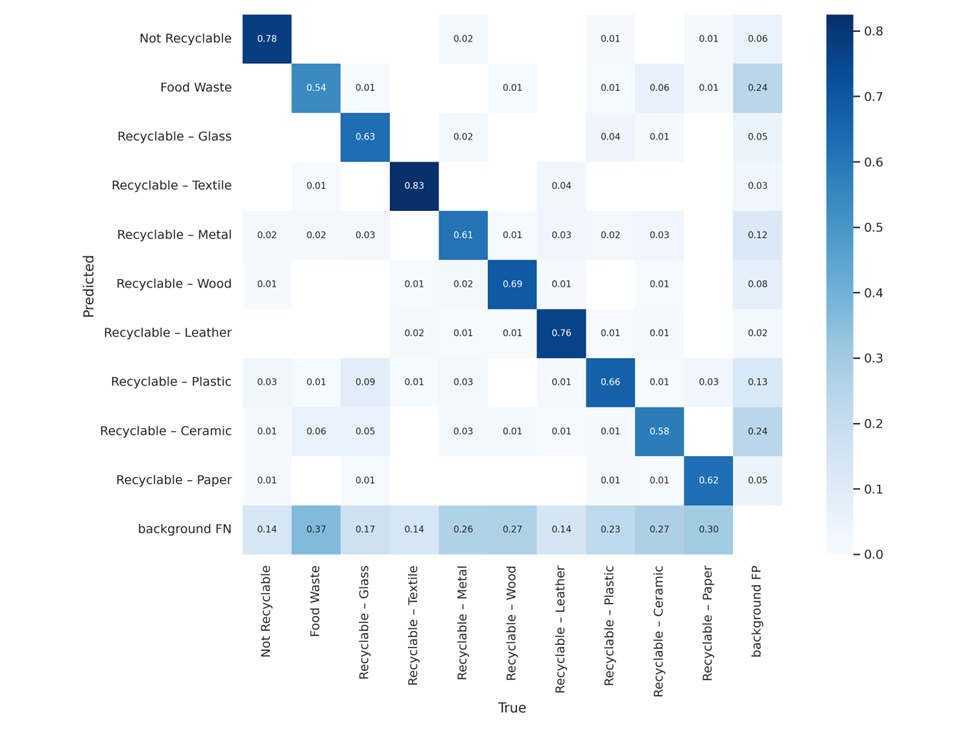
My final main contribution was switching to a different YOLOv5 model, as recommended by John. John found a paper tackling a similar problem, which provided a much larger dataset (almost 10,000 samples compared to the 1500 of the TACO dataset) as a part of its methodology. While there were also model files included, the documentation was incomplete in addition to the fact the model’s parameters were not labeled in English, which discouraged using them directly. I tinkered with some settings and trained a YOLOv5s model from scratch on the new dataset, which seems to be an improvement thus far. Note that I had to adjust our main inference script to accommodate the different waste categories of the new model. The new categories (food waste, textile, wood, leather, and ceramic) are all treated as trash for our project’s scope. Nevertheless, I do not anticipate the model will detect said classes as it is unlikely we will supply them during our testing.
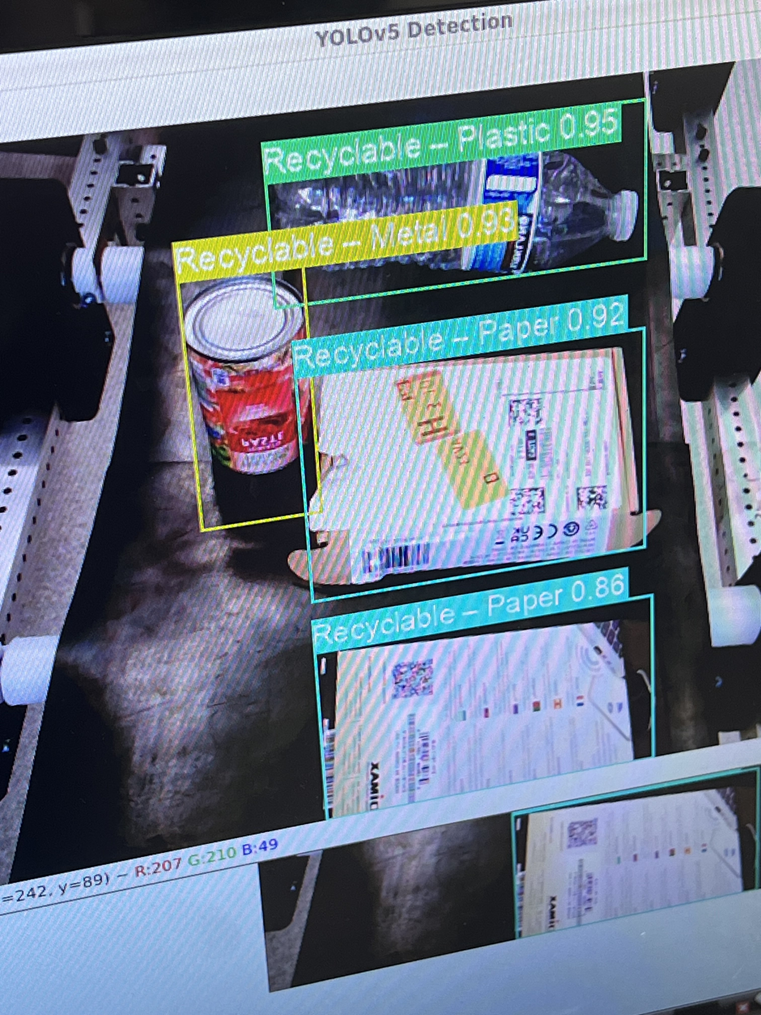
Finally, I helped Erin with fixing our motor speed issues in addition to interfacing between the YOLO script and UI plus actuators.
Additional Question
I did have to learn many things on the fly, such as fine-tuning and training a YOLO model, setting up a Jetson with CUDA from scratch, in addition to using a non-plug and play high-end camera. To be brutally honest, a lot of that learning has been facilitated by generative AI. For example, while I have used YOLO before for another project, ChatGPT helped guide me more depth through the different scripts of YOLOv5 in addition to resolving some bugs here and there. Furthermore as a Windows user, having a co-pilot for navigating certain Linux features (e.g. v4l2) has been a treat. Other than that, I did watch videos as well as read papers forum posts to learn other things, such as interfacing with the Oak-D cameras and getting RGB to work on the SR. Reading research papers was especially helpful in setting up and improving our object detection model.
Mohammed’s Status Report for April 12th, 2025
This week I worked on interfacing with the Oak-D SR in addition to setting up CUDA on the Jetson Nano. The Oak-D camera gave us trouble during the interim demo, leading us to temporarily swap it for a more generic webcam. I managed to get it working after using a high bandwidth USB 3.0 to USB type C, whereas I was previously using a generic USB type C cable. As of right now I have only managed to run the DepthAI Viewer program provided by Luxonis, which demos the camera on a stock YOLOv8 model.
Regarding the Jetson, inference on CUDA was not working initially as mentioned in the Team Status Report. As it turns out the version of OpenCV installed on the Jetson by default does not have CUDA support. While I tried to install the necessary packages to enable it prior to the demo, I did not see much success. As building the package from scratch was obnoxious and often riddled with compatibility issues, I opted to instead reflash the Jetson with a firmware image I found on GitHub that had all the prerequisites pre-installed. Following the reflash I confirmed that CUDA was enabled before reinstalling Wi-Fi compatibility and the Arduino IDE for interfacing with the actuators.
Next week, I hope to integrate the Oak-D SR camera into the cohesive system instead of the webcam we have been using thus far. The Oak-D does have promising depth perception which can be used to determine the front-most object in the belt should our current approach that uses the YOLO bounding boxes fail. As I got CUDA working, I am not particularly interested in running our YOLOv5 mode natively on the camera as that may be riddled with compatibility issues (the demo does have YOLOv8 instead of v5).
Regarding verification plans for the object detection and classification sub-system, I want to re-run the program used for the interim demo to begin benchmarking the inference speed with GPU acceleration as CUDA works now. This corresponds to the “System runs inference to classify item < 2 seconds” requirement mentioned in the Team Status Report. Additionally, I want to benchmark the model’s current classification accuracy to determine if additional fine-tuning is necessary. As outlined in the design presentation, this will be done through 30 trials on assorted objects, ideally representing the classes of plastic, paper, metal, and waste equally. The objects will be moving on the belt to better simulate the nature of the final product.
Mohammed’s Status Report for March 29th, 2025
This week I primarily worked on improving the YOLO model’s performance through additional fine-tuning in addition to testing it in a real-time setting through a webcam attached to my laptop. Compared to a few weeks ago, the model is performing better in classifying paper, plastic, metal, and waste (general trash). However, it still struggles with classifying glass particularly, most likely as there are not many images with glass objects in them in the TACO dataset. Additionally, through testing the model’s inference on a live camera viewing, I have noticed that it performed best at an elevated angle that looked down on the objects for classification. I believe that to be case based on the images in the TACO dataset, which were captured at a similar perspective. By that, I experimented with multiple angles and elevations with respect to the objects to determine the best one, which we hope to deploy in the conveyor belt itself.
To train the model more efficiently, I stopped using Google Colab and set up an environment that trains on John’s home desktop as it does have hardware comparable to an NVIDIA T4, which has been working great so far. Special thanks to John for offering!
Additionally, I was helping the team out with putting everything together for the intermin demo.
Going beyond the interim demo, I hope to improve the model’s precision and recall further in all the object classes. This may need some data augmentation for certain classes, particularly glass. I also hope to test the model’s performance on other datasets not used for training.
Mohammed’s Status Report for March 22nd, 2025
This week I have been fine-tuning the pre-trained YOLO model we initially used as a proof of concept. I used the training files included in the YOLOv5 repo by Ultralytics, which provide neat prediction and losses visualizations. I am monitoring the model’s progression and visual results on my linked WandB account. Dataset wise, I used the TACO dataset with revamped labels which I defined last week. Before using the dataset though I had to split it by training / validation / testing. At the moment, 70% of the dataset is used for training, 20% is used for validation, and 10% is used for testing, where the original dataset contains approximately 1500 images. The shuffling of images and splitting was done using a Python script I wrote, similar to the one used for relabeling the .txt label files. The final addition to the dataset was writing a custom yaml file following Ultralytics formatting to specify the classes and data locations. Putting it all together, I assembled a Python Notebook file on Google Colab running on a T4 GPU for training, which seems to train efficiently as a single epoch takes under 5 minutes with my current settings.
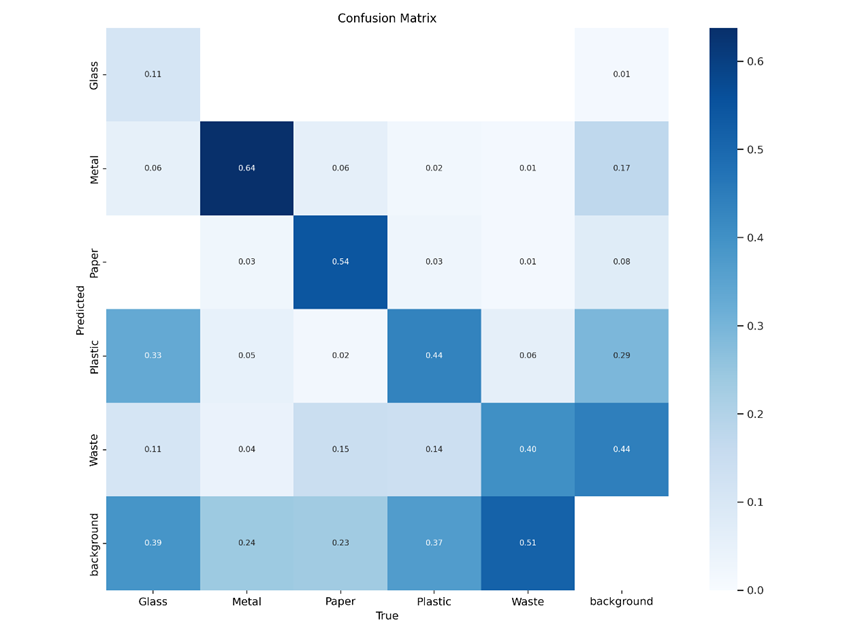
In terms of evaluating our fine-tuned model’s performance, the current script provides both object loss and classification loss for training and validation. Furthermore, the script provides precision and recall which provide further judgement beyond accuracy. Following the conclusion of training, validation, and testing, a confusion matrix is produced, also shedding light on performance with respect to ground truth and false predictions. Following training on a few epochs, we are already seeing some improvements in terms of reducing the losses. Of course, judging the model’s overall performance is also possible through inspecting the intermediary predictions the model gives for both training and validation.


Next week, I hope to continue training to obtain a satisfactory model following the evaluation metrics provided by the Ultralytics script. Furthermore, I aim to maybe use a platform other than Google Colab for training as GPU resources is subject to availability, unless I pay for a credit and/or a Pro account. I am considering using the ECE machines as they also do have T4 GPUs though the process can be finnicky from what I have been told.
Mohammed’s Status Report for March 15th, 2025
This week I worked on finalizing the data-loader for the YOLO model. All the data has been relabeled to fit our targeted categories. Additionally, I have compiled the necessary files for fine-tuning (using the re-labeled data) following the convention outlined in the model’s original publication. Fine-tuning can begin as soon as desired at this point.
In case the obtained annotated data through the TACO dataset is insufficient, I did also find some additional databases that were used to train other models. While the sheer amount of data is less in those datasets, it nevertheless can contribute to improving our model. Utilizing them will require creating annotation files from scratch though.
Next week I hope to continue fine-tuning the model and also get the Oak-D SR working with our Jetson and running inference. We did not have access to both due to ANSYS Hall being closed for the week.
Mohammed’s Status Report for March 8th, 2025
This week I worked on the design report alongside the rest of the team. I have also been getting started with the Oak-D SR (on my laptop for now) as we have just received it from the course inventory. Beyond that, I have been working on making the labels of the annotated trash in the TACO dataset consistent with the project’s categories (those being trash, metal, paper, plastic, and glass). I could be doing better in terms of fine-tuning the model, so that will be my focus for the upcoming week. I hope to bring a noticeable improvement in the model’s categorization of trash particularly as that has been the most problematic category.
Mohammed’s Status Report for February 22nd, 2025
This week I worked on finalizing the parts required for the project alongside the rest of the team. I particularly focused on the embedded / electronic parts in addition to the vision component. Past that, I have been working on the data-loader that compiles the datasets for fine-tuning the model. The fine-tuning itself will happen this week.
Mohammed’s Status Report for February 15th, 2025
Aside from working on next week’s presentation, I primarily experimented with different pre-trained models that can be utilized for the project. The two prominent ones were a YOLOv5 model and a vision transformer, though both were trained on similar datasets. Both models seemed to struggle a bit with trash detection as well as false positives for recyclable material. Fine-tuning the models will likely help with that. The fine-tuning data will likely consist of the dataset that the models were trained. We will also use the Trash Annotations in Context (TACO) dataset which consists of a large image collection of labeled trash and recyclable objects, where we will have to condense the latter to the categories we are using for the project (trash, paper, metal, glass, and plastic).
Attached is an image of the YOLOv5 model’s inference result on an image I captured. The aforementioned problems can be seen in the image. Regardless, we will be sticking with a YOLO model as it is easier to fine-tune and can better visualize its predictions.

Mohammed’s Status Report for February 8th, 2025
Personal Accomplishments
I worked alongside Erin on a Jetson Nano we had to get familiar with the device setup. Obstacles we faced along the way as mentioned in the team report is our first power brick not supplying enough power, leading to impromptu shutdowns, in addition to the device not supporting Wi-Fi natively. Our accomplishment in that regard was fixing the power issues and successfully setting up a wireless connection. Subsequently, I got a YOLO v3 model working on OpenCV by setting up Anaconda and installing any required dependencies.
Lastly, I worked alongside the rest of the team on refining the project’s design and picking the necessary components that we will be ordering, both from 18500’s inventory and internet listings.
Schedule
We are not behind by much now. The design presentation is coming up in under two weeks, which prompted us to begin finalizing our design choices. We expect to wrap up our project design and the corresponding presentation on time. As we are on track for the design presentation, we also expect to order our parts for prototyping soon.
For my part, I will begin compiling databases for our CV model in addition to finalizing the YOLO version that will go utilized.
Next Week’s Deliverables
I hope to complete the design presentation alongside the group. I also aim to have a compiled dataset on recyclable material for our model to learn off. Finally, I would like to help the team finalize the required parts for us to place the order.