
This week I have been fine-tuning the pre-trained YOLO model we initially used as a proof of concept. I used the training files included in the YOLOv5 repo by Ultralytics, which provide neat prediction and losses visualizations. I am monitoring the model’s progression and visual results on my linked WandB account. Dataset wise, I used the TACO dataset with revamped labels which I defined last week. Before using the dataset though I had to split it by training / validation / testing. At the moment, 70% of the dataset is used for training, 20% is used for validation, and 10% is used for testing, where the original dataset contains approximately 1500 images. The shuffling of images and splitting was done using a Python script I wrote, similar to the one used for relabeling the .txt label files. The final addition to the dataset was writing a custom yaml file following Ultralytics formatting to specify the classes and data locations. Putting it all together, I assembled a Python Notebook file on Google Colab running on a T4 GPU for training, which seems to train efficiently as a single epoch takes under 5 minutes with my current settings.
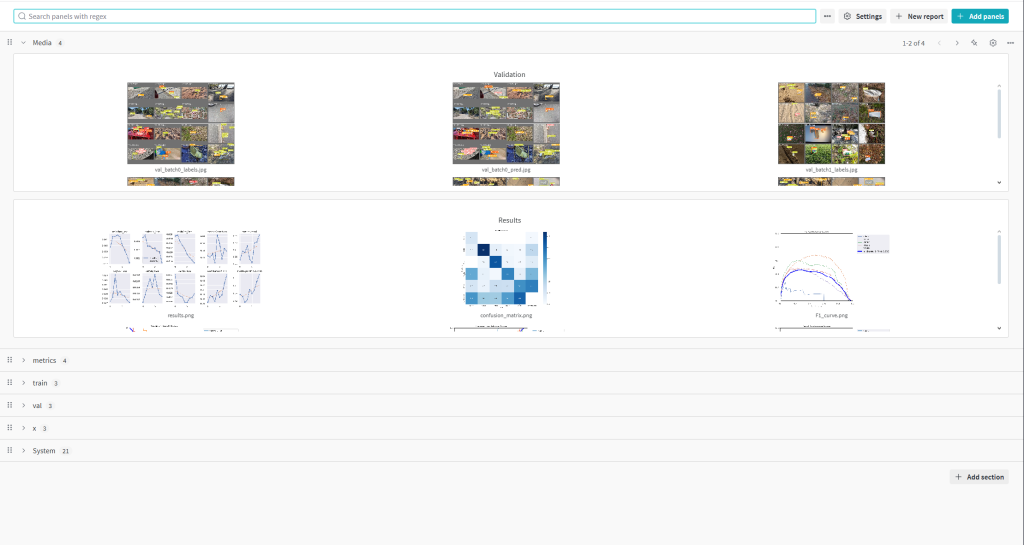
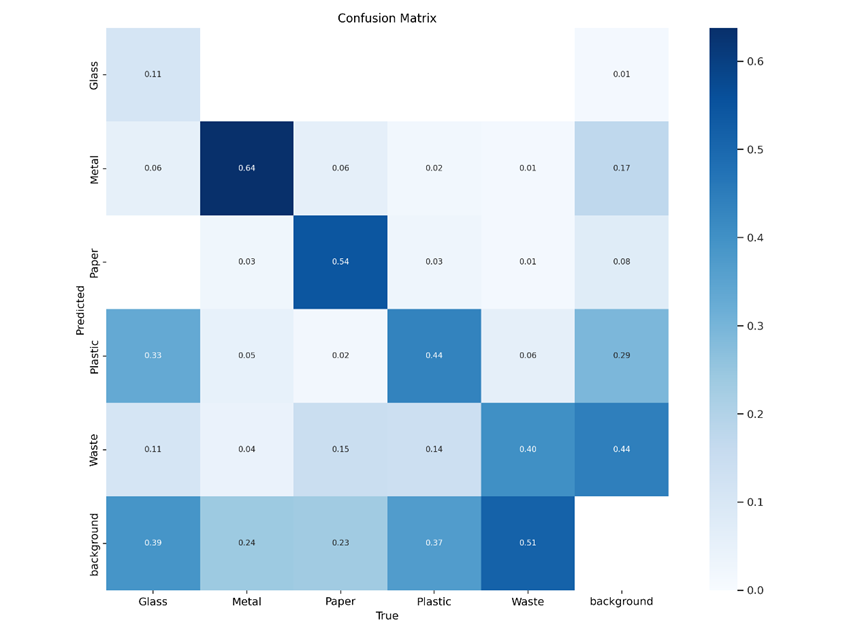
In terms of evaluating our fine-tuned model’s performance, the current script provides both object loss and classification loss for training and validation. Furthermore, the script provides precision and recall which provide further judgement beyond accuracy. Following the conclusion of training, validation, and testing, a confusion matrix is produced, also shedding light on performance with respect to ground truth and false predictions. Following training on a few epochs, we are already seeing some improvements in terms of reducing the losses. Of course, judging the model’s overall performance is also possible through inspecting the intermediary predictions the model gives for both training and validation.


Next week, I hope to continue training to obtain a satisfactory model following the evaluation metrics provided by the Ultralytics script. Furthermore, I aim to maybe use a platform other than Google Colab for training as GPU resources is subject to availability, unless I pay for a credit and/or a Pro account. I am considering using the ECE machines as they also do have T4 GPUs though the process can be finnicky from what I have been told.