
This week I worked on Docker and some VM stuff. Throughout the week I tried to fix the docker container to run Ollama inside, but to no avail. Me and Justin also tried working on it together, but we weren’t able to fully finish it. Justin was able to fix it later, and I was also able to make a working version as well, although we are going to use Justin’s version as the final. The main issue for my version was that my gpu wasn’t running with the model in the container. I fixed this by not scripting ollama serve in the Dockerfile initially, and just downloading Ollama first. Then I would be able to Docker run with all gpus to start my container. After that I could pull the models and also run Ollama serve to have a fully functional local docker container working. If we were to have used this version I could script the pulling and running of Ollama serve to occur after running Docker. Earlier in the week I also tried to get a vm with a T4 GPU on gcp. However, after multiple tries across servers, I was not able to successfully acquire one. Me, Kemdi, and Justin also met together at the end of the week to flesh out the demo which is basically fully working. I am on schedule, and my main goal for next week is to get a 3d printed container for the board and speaker/mic through FBS.
Kemdi Emegwa’s status report for 3/29
I spent this week doing a lot of different things mostly pertaining to the device, in addition we did an end to end test.
Firstly, as I mentioned last week we decided to upgrade back to a Raspberry pi 5 from the Raspberry pi 4 we had been using because the Raspberry pi 4 was not delivering the performance we wanted. I spent a bit of time configuring the new Raspberry pi 5 to work with our code and with the speakerphone we bought last week. Once I got it working, I test the Text to Speech models which were the reason we made the switch in the first place. Piper TTS, which was what I had wanted to move forward with previously was a lot faster, but still had a noticeable delay even when streaming the output. I plan on doing more research on faster text to speech models, but for right now we are using Espeak, which provides realtime tts, albeit at worse quality.
In addition, I started to think about how a user would approach setting up the device when they first get it. Operating under the assumption that the device was not already connected to wifi, the user needed a way to access the frontend. This posed a challenge. I did some research and found a solution: Access point mode.
Wifi devices can operate in 1 of 2 modes at any given time. Client mode And access point mode. Typically for our devices we use client mode and routers use access point mode, but by leveraging access point mode we are able to allow the user to access the device frontend without a wifi connection.
How this works is that when the device starts up and detects it is not connected to wifi it will activate access point mode. This emits a network that the user can connect to by going into the wifi settings and inputting a password. They then just have to go their browser and input the ip address/port where the flask server is being hosted. I have written scripts to automate starting up access point mode and turning it off, but more needs to be done to allow the device to detect it is not connected to wifi and use those scripts.
In the same vain of user experience, I configured the raspberry pi so that our scripts run on startup/reboot. This eliminates the need of a monitor to run the code, which is the way we envision users interacting with our project anyways.
Lastly, as a group we did a full end to end test with a cloud hosted open source model. We were able to test all our core functionalities, including regular LLM queries, music playback and alarms.
I don’t for see any challeneges upcoming and I believe we are on track. This upcoming week will be spent researching more TTS models, allowing the device to detect that it is not connected, and error handling.
Team Status report for 3/29
This week we spent getting everything ready for the demo and doing e2e tests to make sure everything is setup and ready. We got everything to work for the demo where the user can talk to the assistant to have a conversation, set/stop an alarm, or play/stop playing a song. We also got a VM with a GPU setup where we are doing model inference for quicker performance (for the demo we will be using llama3.2 with 8b params). We also made some updates to our UI for a better user experience. This week we did lots of integrations and putting everything together for the first time and are very pleased with our results.
We don’t foresee any big risks or challenges up ahead as we were able to overcome our biggest challenges which were getting the mic and speaker to work and to integrate all parts of the system together. One small issue that we may see is that we had set our latency requirements to be under 5 seconds, but lots of our current tests are a little bit over this. We are looking into changing text to speech models to a smaller one as it is a big bottleneck in our system right now and are also looking into streaming our responses from the model instead of waiting for the response to be fully complete which might give us some extra performance.
No changes were made to the existing design of the system this week.
Justin Ankrom’s Status Report for 3/29
This week I worked on getting things ready for the demo. First I worked on adding some new sections to the main website people can visit to learn about Voice Vault. I added a section describing what our product is and another section on how to setup the device. I also added the top nav bar to navigate through all the sections: 

I also worked on setting up the pages needed for the device website. Originally, I had setup just one page after the user logged in where they could adjust their VM url and see their music. This week I worked on overhauling how this works. I made it so the home page just had 2 buttons where the user can change their configuration settings or go to the music page. This looks like this:



I also implemented functionality on everything on the settings page to be saved locally so we can access it later, but the functionality to actually change all the configs internally hasn’t been implemented yet. For example I can change the wake word and it will save but it won’t actually change the wake word being used by the device.
This week I also worked extensively with David to try and get our models containerized. I worked on developing the actual docker files being used and the docker compose. I came up with a solution found here: https://github.com/jankrom/Voice-Vault/commit/7501d4eebc4cd480b79e89e9fdfd27402f51c14f. With this solution, we just need to run “MODEL=“smollm2:135m” MODEL_TAG_DOCKER=“smollm2-135m” docker compose up –build” where we just change what the env variables to change which model is being downloaded form ollama. This makes it much more flexible and really easy for us to make new model containers. We struggled a lot trying to build this and get it to work. WE also had a lot of trouble to get ollama to use the GPU, so we spent many hours doing this. But we eventually got it to work. I then also spun up a VM on GCP with a GPU and set up up a container using llama3.2 8b version which we will use for the demo.
Lastly, I worked together with David and Kemdi doing final touches on getting everything ready for the demo. This included testing everything end to end for our 3 main features (talking to model, setting alarm, playing music) and fixing stuff as they came up. Ultimately, we got everything done we wanted to for the demo.
My progress is on schedule. Next week I want to do the prompt engineering tests to find the best prompt for us to use. I also want to finish the VM setup guide and I wand to finish up the main website to no longer include some placeholder values for the models (which will also include making all the model containers).
Justin Ankrom’s Status Report for 3/22
This week I accomplished 2 main things: setting up the alarm clock feature and setting up the terms of service. I setup an alarm clock so that the user can use their voice to set an alarm and cancel it. Here is the code for it: https://github.com/jankrom/Voice-Vault/commit/154f069886dcc4a63c505fd4d009cbf75d0b61fd. This involved researching how to make an alarm clock that works asynchronously without blocking behavior. This actually proved more difficult than anticipated because almost all solutions online are synchronous, meaning they blocked the behavior of the script. Finally I came up with this working solution. I also tested it both on my computer and also on device and it works. I also worked on getting the terms of service up which looks like this: 

I used what I learned from my talk with Professor Brumley and included everything that we discussed. This essentially included making it very clear to the user how their data is being used and that they agree to this. I had also hoped to get the VM setup documentation done this week but I had a very busy week with exams and other coursework this week so wasn’t able to get as much done as I would’ve hoped. Next week I will make up for this by completing the VM setup on top of what I had planned, which will bring me back to schedule. Next week I will work with David and Kemdi to get everything up and running for the demo week the week after next week. This will include putting all necessary code onto the device, integrating all our solutions, hosting a model on the cloud, and do tests to make sure everything is working. Our goal is to have a fully working solution by demo day (I am hopeful that we can get this done).
Team Status report for 3/22
This week was largely spent making the Raspberry pi work with our code. We were able to mitigate our largest problem we were facing, which was that we were not able to programmatically input or ouput audio through the Raspberry pi. This meant that even though we could test the code on our laptops, we couldn’t verify it on the device. However after a lot of time configuring, we were able to achieve just that.
A few changes were made to our desing, we intially planned to use a Raspberry pi5, but that was stolen and we were left with a Raspberry pi 4, we have decided to go back to using a Raspberry pi 5. The TTS models that allow for reasonable quality and clarity simply do not run fast enough on a Raspberry pi 4. Our than this there is unlikely to be any major chnages upcoming.
We are in a good position and we don’t for see any major challenges heading our way. The biggest risk right now is trying to integrate the entire system.
Kemdi Emegwa’s status report for 3/22
This week I mainly spent finally getting the audio to work on the raspberry pi. After spending a considerable amount of time trying to get our old separate mic/speaker setup to work, we eventually decided to just transition to a 2 in 1 speakerphone. Eventhough, we were initially led to believe this would not work, I was able to spend sometime configuring the raspberry pi to recognize the speakerphone to allow for programmatic audio input/output. I was finally able to start testing the capabilities our our program. However, I had to spend quite a lot of time getting the TTS models working on the raspberry pi. This required tirelessly searching for a version of Pytorch that would work on the raspberry pi.
Since I was able to finally get the device inputting and outputting audio, I decided to start benchmarking the TTS(Text-To-Speech) and ASR(Automatic Speech Recognition models we were using. As mentioned in our previous post we switched from pocketphinx/espeak for ASR/TTS to VOSK/Coqui TTS. Vosk perfomed in line with what we wanted to allowing for almost real time speech recognition. However, Coqui TTS, was very slow. I tested a few different TTS models such as piper-tts, solero-tts, espeak, nanotts, and others. Espeak was the fastest but also the worst sounding, while piper-tts combined speed and performance. However it is still a bit to slow for out use case.
To combat, this issue we are looking to transition back to using a Raspberry pi 5, after our last Raspberry pi 5 was stolen and we were forced to use a Raspberry pi 4. I think we are definitely on track and I will spend next week working on integrating querying the LLM with the devie.
David’s Status Report for 3/22
This week I worked on the model/server code. From last week, I was initially trying to get the downloaded model from hugging face running locally. However there were many issues, dependencies, and OS problems. After trying many things, I did some more research into hosting models. I came across a software named Ollama, which allowed for easy use of a local model. I coded some python to create a server which took in requests to run through the model and then return to the endpoint.
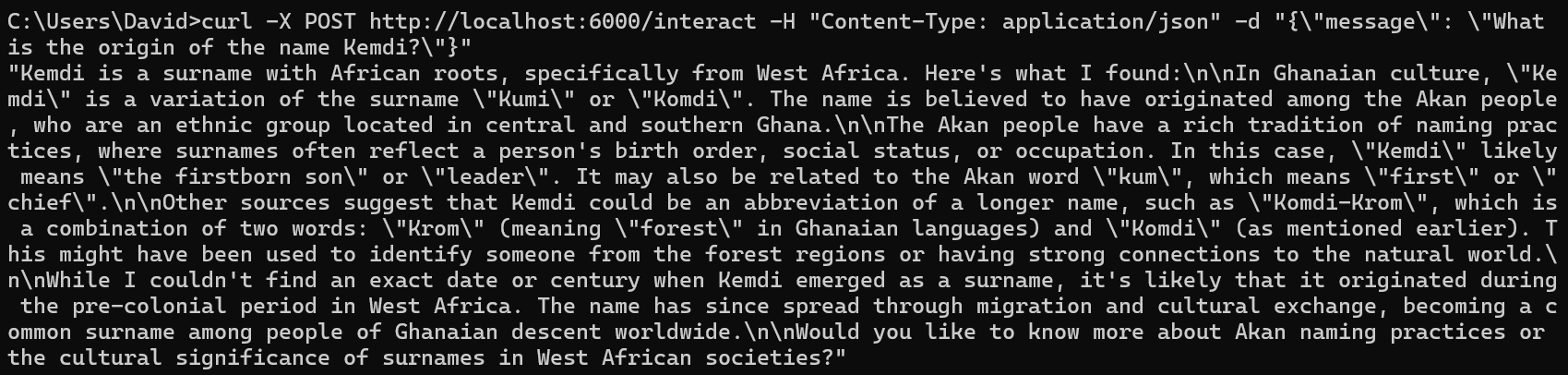 As seen here, we can simply curl a request in which will then be parsed into the model and returned. I then tried to look into dockerization of this code. I was able to build a container and curl into its exposed port, yet the trouble I come across is that the Ollama code inside does not seem to be running. I think it stems from the fact that to run Ollama in python, you need two things (more like three things): Ollama package, Ollama App and related files, and an Ollama model. Currently, the Ollama model and App are on my pc somewhere, so when I initially tried to containerize the code the model and app were not included, only the Ollama package (which is useless by itself). I then tried pasting those folders into the folder before building the Docker image, and they were still not running. I have played around with mounting images, and other suggested solutions online, but they do not work. I am still researching into fixing it, but there are few resources that pertain to my exact situation as well as my OS(windows). We are currently on schedule.
As seen here, we can simply curl a request in which will then be parsed into the model and returned. I then tried to look into dockerization of this code. I was able to build a container and curl into its exposed port, yet the trouble I come across is that the Ollama code inside does not seem to be running. I think it stems from the fact that to run Ollama in python, you need two things (more like three things): Ollama package, Ollama App and related files, and an Ollama model. Currently, the Ollama model and App are on my pc somewhere, so when I initially tried to containerize the code the model and app were not included, only the Ollama package (which is useless by itself). I then tried pasting those folders into the folder before building the Docker image, and they were still not running. I have played around with mounting images, and other suggested solutions online, but they do not work. I am still researching into fixing it, but there are few resources that pertain to my exact situation as well as my OS(windows). We are currently on schedule.
Kemdi Emegwa’s status report for 3/15
This week I spent a lot of time testing and making changes. After extensive testing I determined that the current solutions we were using for speech to text and text to speech were not going to be sufficient for what we want to do. CMU Pocketsphinx and Espeak simply did not allow for the minimum performance necessary for out system. Thus i made the transition to Vosk for speech to text and Coqui TTS for text to speech.
I spent a lot of time configuring the environment for these two new additions as well as determining which models would be suitable for the raspberry pi. I was able to get both working and tested, which yielded significantly better performance for similar power usage.
In addition, I add the ability to add/delete songs on our frontend for out music capabilities. I also added a database to store these songs.
I am on track and going forward, I plan on testing the frontend on the raspberry pi.

David’s Status Report for 3/15
This week I have worked on setting up the docker container and the software that deals with the model. I currently have working code that can take in a curl request with username and password and if correct the request will then be sent to a model. The model currently is a dummy model that just spits out a number, but once the actual model is put in place it should be working. For getting the actual model, I have requested and downloaded a Llama model from HuggingFace. I am currently working through setting up the model as it needs certain requirements. I have also done some research into new parts for speaker/microphone and have settled on one that should fix our issues. Our project is a little behind due to the hardware not working, and we hope to fix that next week with the new part. I personally hope to accomplish getting the model set up so that the established data flow of a command coming in, authentication checking, running prompt through model, and spitting out result works as intended.

As can be seen in this picture, I send a curl command from terminal and the server receives it and gives back a prediction (from dummy model).